
Les données JSON peuvent être utilisées dans une tâche d'importation, définie dans le chapitre Échange de données de Selligent by Zeta.
Notez que les valeurs contenues dans une structure JSON ne peuvent pas être importées nativement dans des tables de base de données. Le traitement « en arrière-plan » transforme la structure JSON en un ou plusieurs flux CSV, qui alimentent ensuite les colonnes de certaines tables temporaires.
À partir de là, une procédure stockée est nécessaire pour extraire les données opérationnelles de ces lignes, ce qui constitue la partie « traitement des données » du « post-traitement ». Si aucun post-traitement n'est effectué, les données restent au repos dans ces tables temporaires du backend.
Remarque : Ces tables temporaires ne sont visibles que dans l'explorateur de données de Selligent by Zeta (ou dans le volet SQL de Campaign). Les données ne peuvent pas être consultées par les personnes n'ayant pas accès à ces fonctionnalités.
1. Importation d'une seule fiche
À titre d'exemple, nous allons commencer par un fichier JSON simple contenant une seule ligne de données, dont voici un exemple :
{
"fullname" : "Penny Haythere",
"email" : "penny@jmail.nl",
"lang" : "Dutch",
"mobile_number" : "0031 234 567890",
"badge" : "013159"
}Remarque : Vous pouvez télécharger ce fichier JSON ici.
Voici un exemple de XML décrivant la structure JSON de cette fiche :
<LOADFORMAT>
<TABLE PATH="" NAME="Records" ROOTTABLE="1">
<COLUMN PATH="fullname" />
<COLUMN PATH="email" />
<COLUMN PATH="lang" />
<COLUMN PATH="mobile_number" NAME="mobile" />
</TABLE>
</LOADFORMAT>Commencez par créer une nouvelle tâche d'importation, en spécifiant le chemin d'accès comme une URL publique (ce qui évite d'avoir à gérer la mise en place du fichier JSON sur une source FTP) :
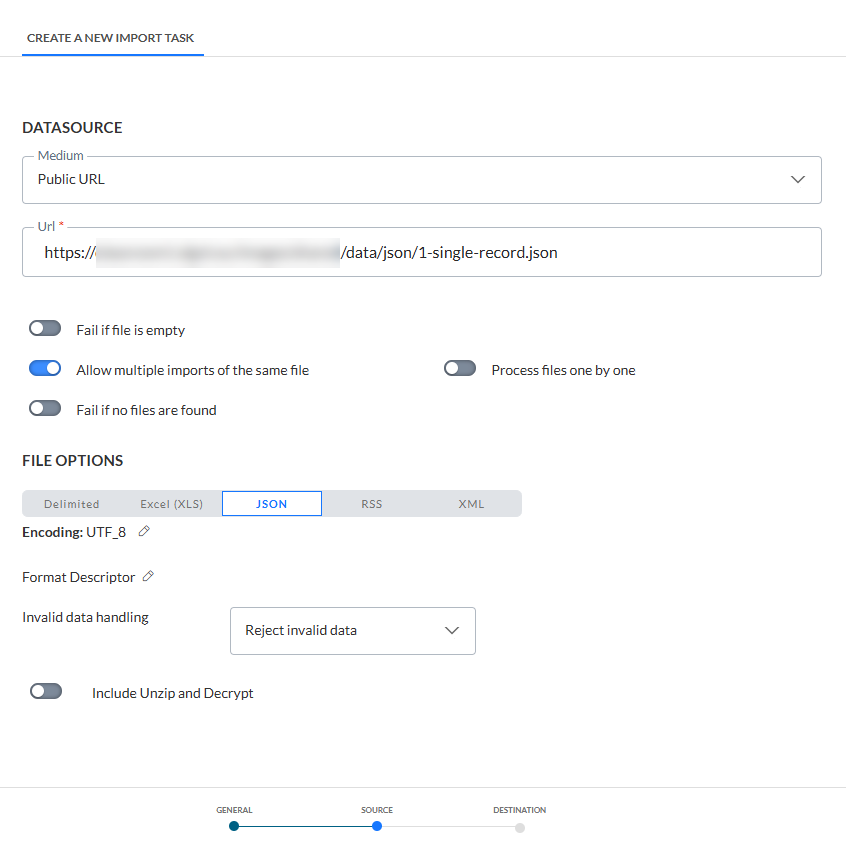
Pour le descripteur de format, nous devrons spécifier le XML qui décrit ce JSON :

Quelques points concernant le XML :
- Chaque clé JSON (fullname, email, etc.) est spécifiée comme une COLONNE dans le XML.
- Une clé omise du XML n'est pas prise en compte pour l'importation. Dans ce cas précis, la valeur JSON de 'badge' est ignorée.
- Une table temporaire est créée, avec les colonnes FULLNAME, EMAIL et LANG.
- La dernière colonne s'appelle MOBILE, car l'attribut 'NAME' spécifie le nom de la colonne. Si NAME est omis, les colonnes sont par défaut les spécifications de PATH (FULLNAME, EMAIL et LANG dans ce cas).
- NAME="Records" indique que le nom de la table temporaire est au format JOB_1234_Records.
- Le numéro du travail est l'ID de travail de Campaign relatif à la tâche d'importation.
Remarque : Cet ID de travail n'est pas visible dans Selligent, bien qu'il s'affiche dans les notifications par e-mail.
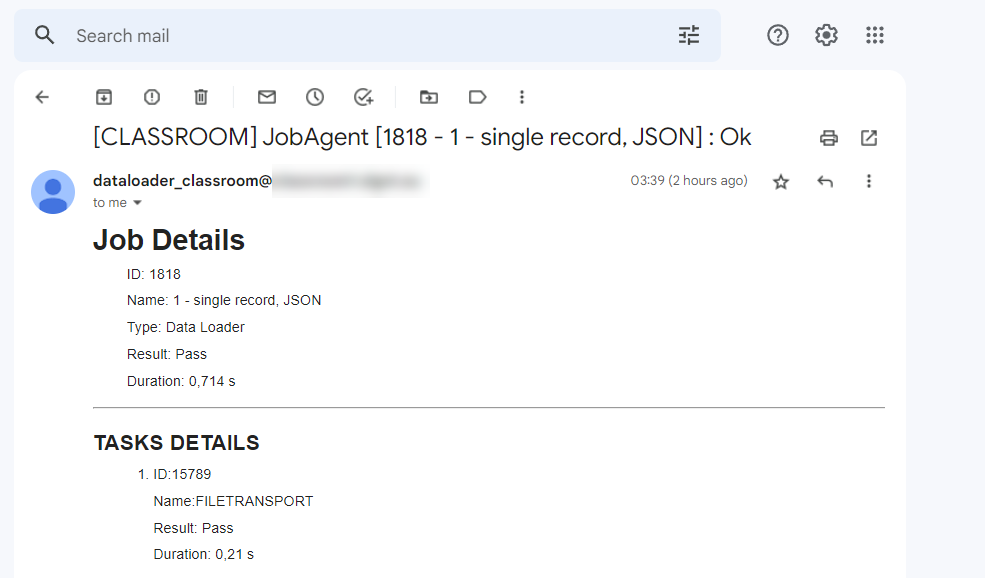
Dans l'exemple ci-dessus, l'iD de travail est 1818, le type Data Loader fait référence à la tâche d'importation, Name étant le nom de cette dernière. - Le suffixe Records a été fourni dans la définition de <TABLE>.
- De nombreux niveaux hiérarchiques peuvent s'afficher dans les données JSON, chacun avec sa propre déclaration <TABLE>, mais tout est inclus dans un seul niveau supérieur désigné par ROOTTABLE=1 et une valeur PATH vide.
- L'élément racine du XML est toujours <LOADFORMAT>, de sorte que toutes les définitions de <TABLE> et <COLUMN> doivent être incluses dans ces éléments.
- Un prologue XML n'est pas nécessaire.
Sur l'écran suivant, le nom de table est requis :

Il ne s'agit pas du nom des tables temporaires où les données résident, mais d'une table intermédiaire contenant des informations sur les tables temporaires créées par les flux CSV. Nous y reviendrons plus tard, mais pour l'instant, nous nous contenterons d'indiquer la mention 'first'.
Remarque : Une vérification est effectuée lors de l'enregistrement de la tâche, en comparant le nom spécifié à un nom qui existe déjà. En cas de collision, Selligent génère une erreur et refuse d'enregistrer la tâche.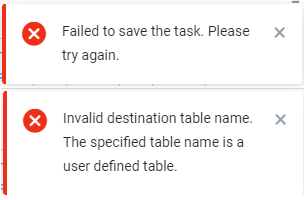
Lorsque le travail est exécuté, l'historique doit confirmer qu'il a fonctionné comme prévu :
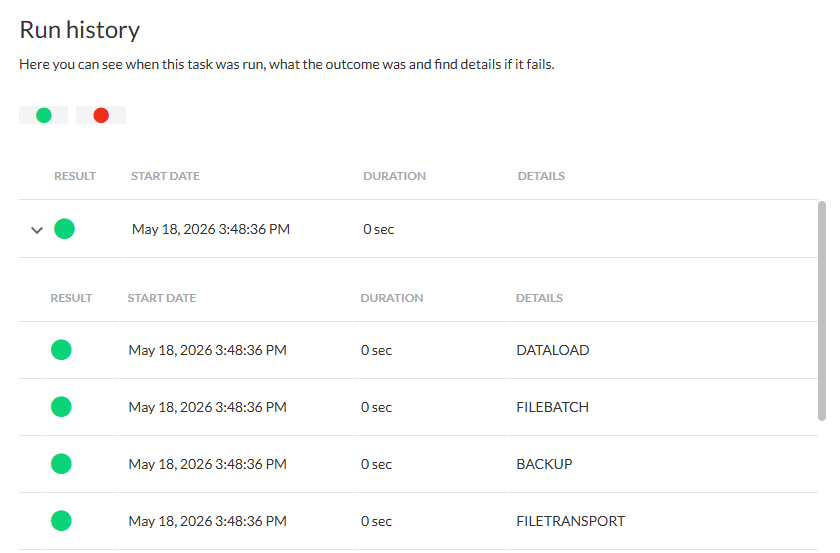
À partir de là, l'explorateur de données peut être utilisé pour afficher ce qu'il est advenu des données. La recherche par le nom spécifié comme table de destination montre qu'une nouvelle table portant ce nom existe déjà :
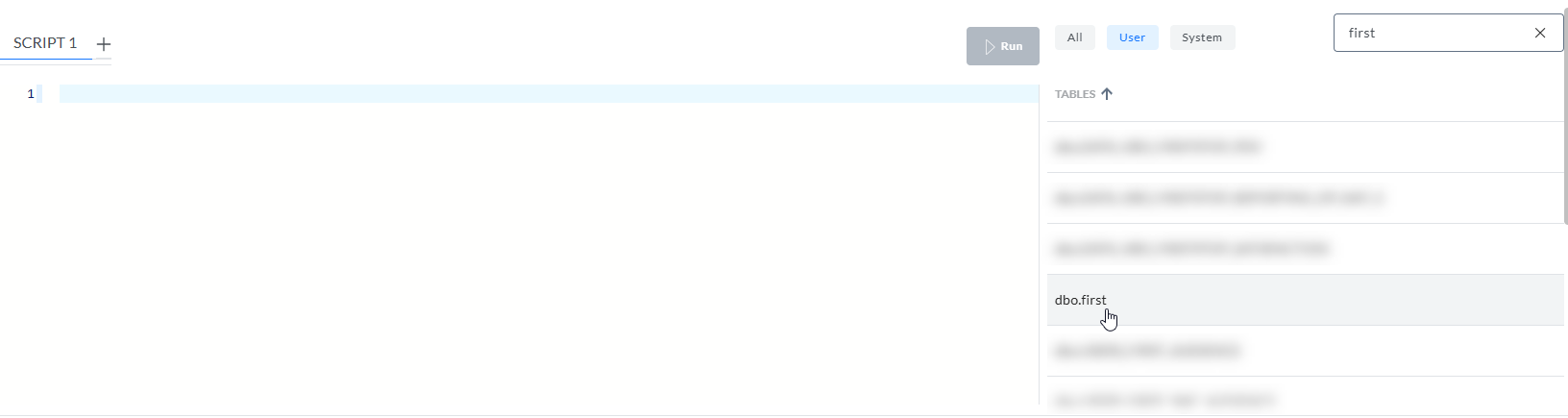
L'interrogation de cette table ne révèle qu'une seule ligne contenant le nom de la table JOB_[ID]_Records (c'est-à-dire un seul fichier CSV) :
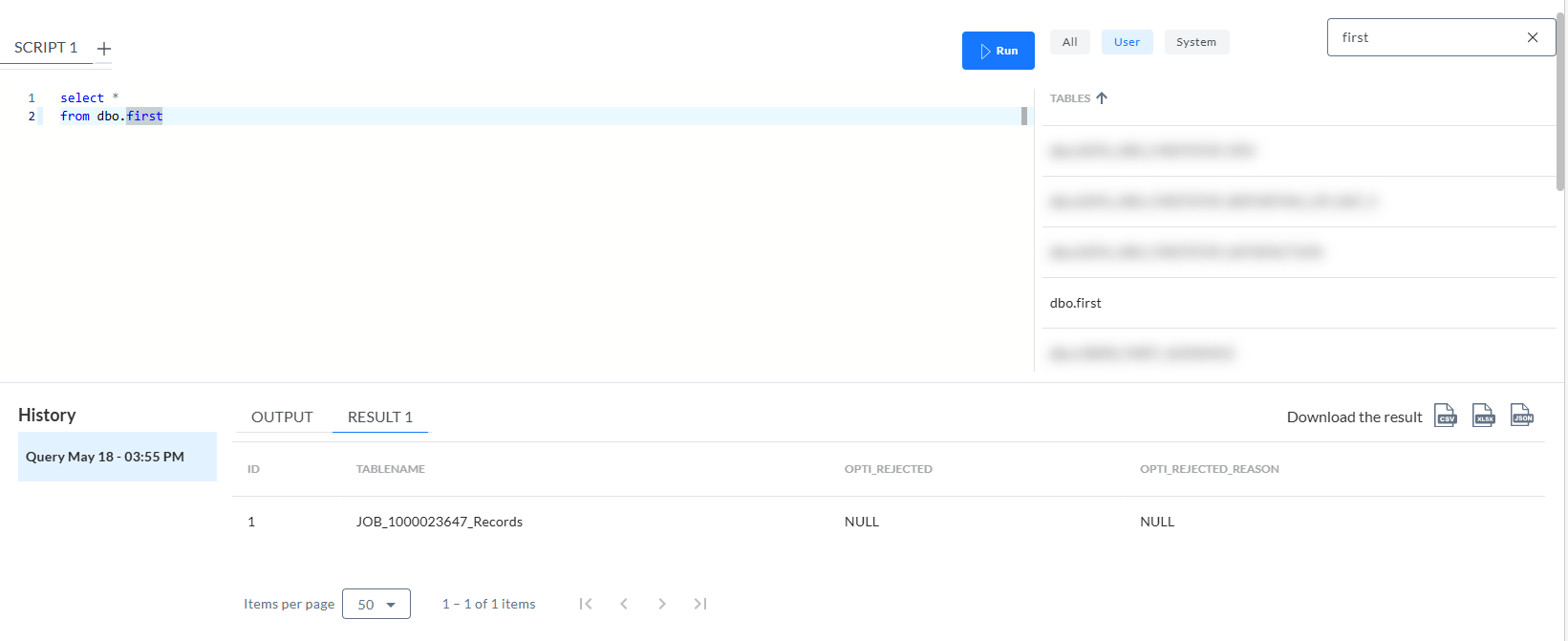
L'interrogation de la table JOB_[ID]_Records affiche les données elles-mêmes :
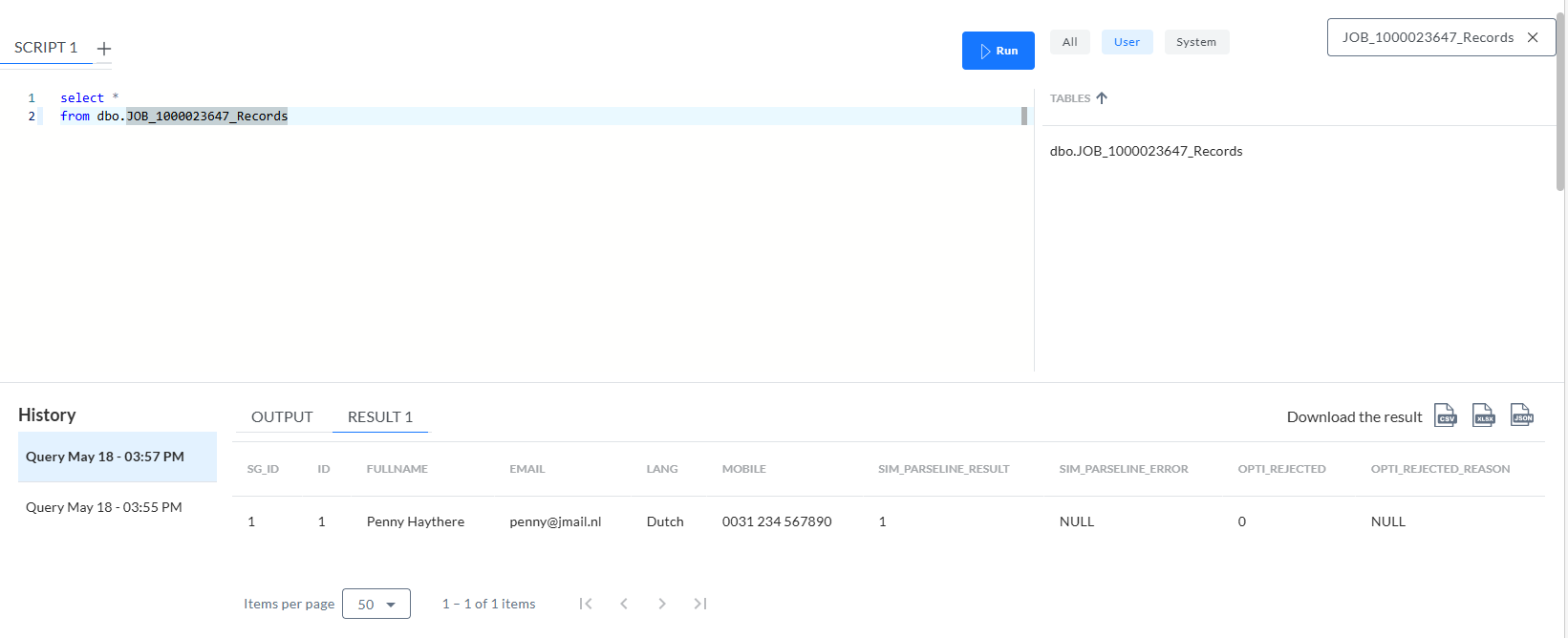
Comme prévu :
- Le nom de la table contient le suffixe _RECORDS du descripteur de format.
- L'attribut NAME a créé la colonne MOBILE.
- Les colonnes FULLNAME, EMAIL et LANG correspondent par défaut aux entrées de PATH, sans aucune indication pour NAME.
2. Importation de fiches multiples
Conservons l'exemple précédent, avec cette fois-ci le fichier JSON contenant des fiches multiples dans un tableau :
[
{
"fullname" : "Dwayne Rodriguez",
"email" : "rodriguez@laredo.mx",
"lang" : "Spanish",
"mobile_number" : "0052 345 667788"
},
{
"fullname" : "Gottlieb Kiesel",
"email" : "dr.kiesel@hesse.edu.de",
"lang" : "German",
"mobile_number" : "0049 123 445566"
},
{
"fullname" : "Fulbert le Fou",
"email" : "inventor@barn.fr",
"lang" : "French",
"mobile_number" : "0033 456 789789"
}
]Remarque : Vous pouvez télécharger ce fichier JSON ici.
Le descripteur de format utilisé pour décrire la structure de données JSON précédente suffit également ici. Mais nous allons faire quelques changements :
<LOADFORMAT>
<TABLE PATH="" NAME="multiple" ROOTTABLE="1">
<COLUMN PATH="fullname" />
<COLUMN PATH="email" NAME="mail"/>
<COLUMN PATH="lang" />
<COLUMN PATH="mobile_number" NAME="mobile" />
</TABLE>
</LOADFORMAT>Dans ce cas :
- Les colonnes FULLNAME, MAIL, LANG et MOBILE sont remplies.
- Elles s'affichent dans une table dont le nom ressemble à JOB_1820_MULTIPLE.
- Le nom de cette table correspond à une ligne unique mentionnée dans la table intermédiaire (nommée « première » précédemment).
3. Fiches multiples avec sous-clés uniques
Dans cette situation, au lieu d'une structure plate, chaque fiche peut contenir des informations supplémentaires spécifiées sous forme de sous-clés (un niveau plus profond), qui peuvent correspondre à des données connexes 1:1 :
[
{
"fullname" : "Dwayne Rodriguez",
"email" : "rodriguez@laredo.mx",
"lang" : "Spanish",
"mobile_number" : "0052 345 667788",
"workdetails" :
{
"office" : "Tijuana",
"payrollNo" : 11223344
}
},
{
"fullname" : "Gottlieb Kiesel",
"email" : "dr.kiesel@hesse.edu.de",
"lang" : "German",
"mobile_number" : "0049 123 445566",
"workdetails" :
{
"office" : "Berlin",
"payrollNo" : 55667788
}
},
{
"fullname" : "Fulbert le Fou",
"email" : "inventor@barn.fr",
"lang" : "French",
"mobile_number" : "0033 456 789789",
"workdetails" :
{
"office" : "Paris",
"payrollNo" : 99001122
}
}
]Remarque : Vous pouvez télécharger ce fichier JSON ici.
Voici un exemple de descripteur de format :
<LOADFORMAT>
<TABLE PATH="" NAME="csvfile1" ROOTTABLE="1">
<COLUMN PATH="fullname" />
<COLUMN PATH="email" />
<COLUMN PATH="lang" />
<COLUMN PATH="mobile_number" NAME="mobile" />
<COLUMN PATH="workdetails.office" NAME="workdetails_office"/>
<COLUMN PATH="workdetails.payrollNo" NAME="workdetails_payrollNo"/>
</TABLE>
</LOADFORMAT>
Nous allons spécifier une table intermédiaire avec le nom 'multiple' :
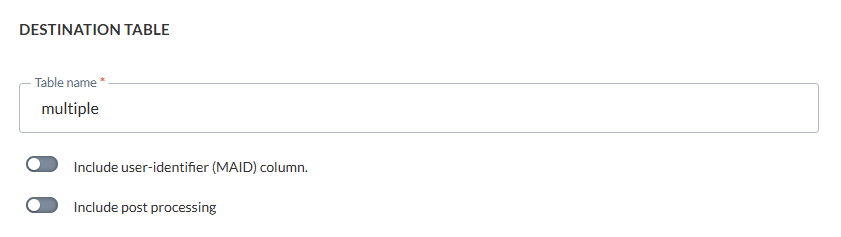
Une fois le travail exécuté, la table 'multiple', contient une ligne : JOB_[ID]_csvfile1.
En interrogeant la table JOB_[ID]_csvfile1, nous voyons ceci :
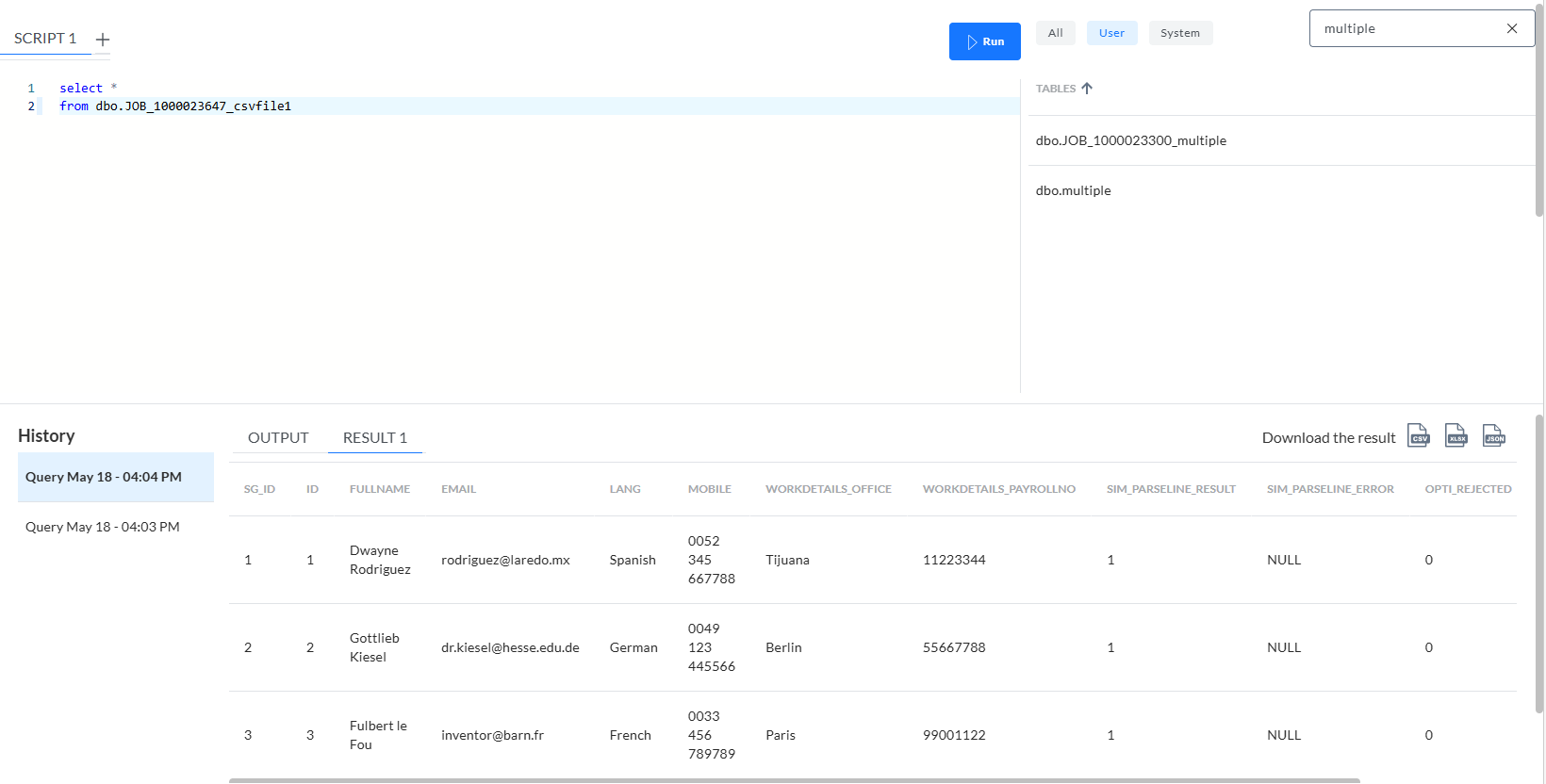
Remarque :
- PATH="workdetails.office" utilise un point comme séparateur de niveau.
- NAME="workdetails_office" est le nom donné à la colonne de la table créée dans cette table de retenue.
- Csvfile1 est le nom donné à cette table par le descripteur de format.
4. Fiches multiples avec sous-clés multiples
Cette fois, le fichier JSON contient des fiches multiples. Chaque fiche peut également contenir un tableau de fiches multiples liées, simulant une relation 1:N.
[
{
"fullname" : "Dwayne Rodriguez",
"email" : "rodriguez@laredo.mx",
"lang" : "Spanish",
"mobile_number" : "0052 345 667788",
"subscriptions" : [
{ "magazine" : "GH", "start" : "2016-01-10" }
]
},
{
"fullname" : "Gottlieb Kiesel",
"email" : "dr.kiesel@hesse.edu.de",
"lang" : "German",
"mobile_number" : "0049 123 445566",
"subscriptions" : [
{ "magazine" : "GH", "start" : "2017-05-11" },
{ "magazine" : "SI", "start" : "2018-07-12" }
]
},
{
"fullname" : "Fulbert le Fou",
"email" : "inventor@barn.fr",
"lang" : "French",
"mobile_number" : "0033 456 789789",
"subscriptions" : [
{ "magazine" : "GH", "start" : "2019-09-14" },
{ "magazine" : "SI", "start" : "2020-10-16" },
{ "magazine" : "FM", "start" : "2021-11-18" },
{ "magazine" : "KG", "start" : "2022-12-20" }
]
},
{
"fullname" : "Fiona Starr",
"email" : "hellfire@chopper.edf",
"lang" : "EN",
"mobile_number" : "0044 7890 112233",
"subscriptions" : [ ]
}
]
Remarque : Vous pouvez télécharger ce fichier JSON ici.
Voici un exemple de descripteur de format :
<LOADFORMAT>
<TABLE PATH="" NAME="toplevel" ROOTTABLE="1">
<COLUMN PATH="fullname" />
<COLUMN PATH="email" />
<COLUMN PATH="lang" />
<COLUMN PATH="mobile_number" NAME="mobile" />
<TABLE PATH="subscriptions" NAME="related">
<COLUMN PATH="magazine" NAME="periodical"/>
<COLUMN PATH="start" NAME="START_DT"/>
</TABLE>
</TABLE>
</LOADFORMAT>Dans ce cas :
- NAME="toplevel" est le nom donné à la première table par le descripteur de format.
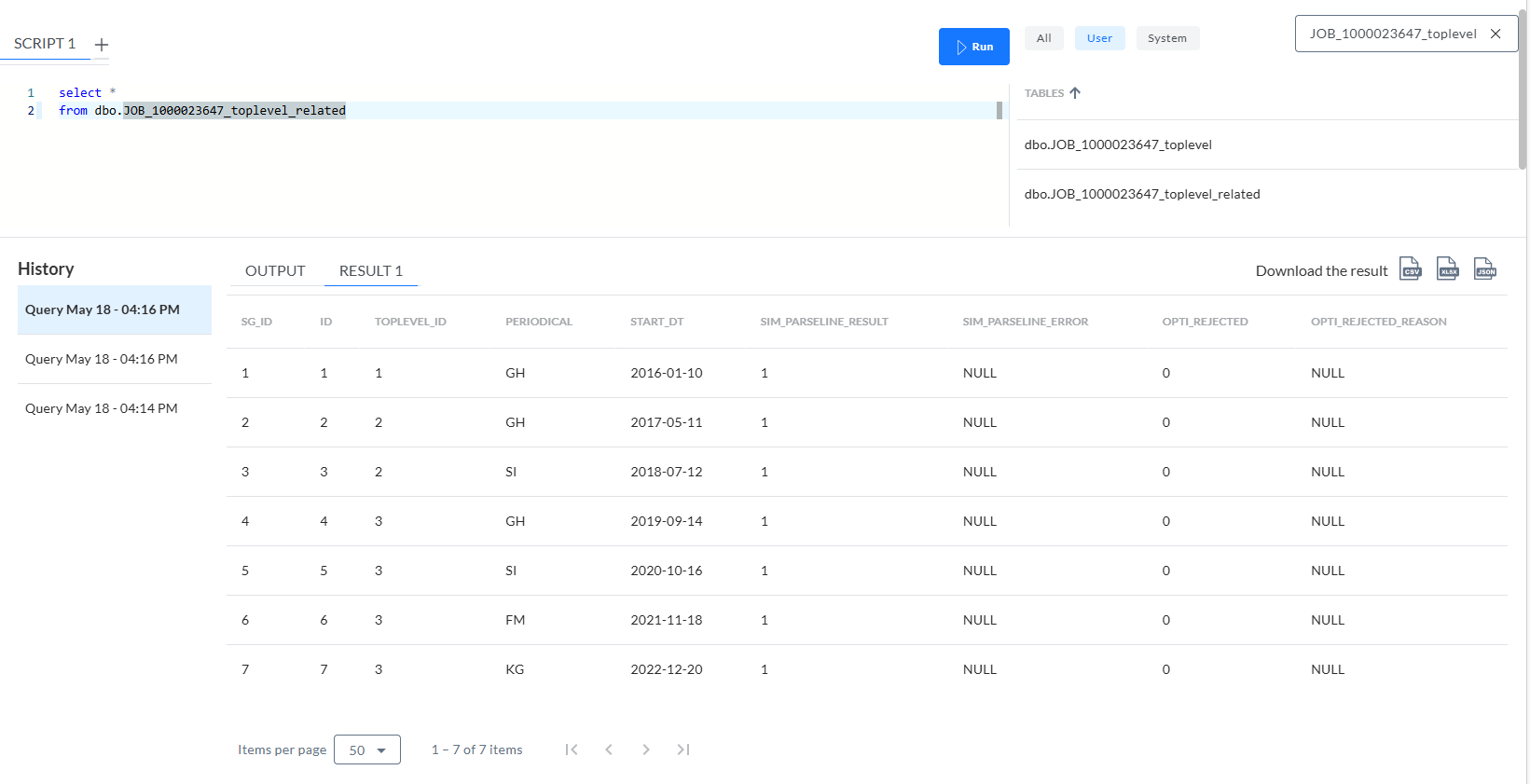
- <TABLE PATH="subscriptions" identifie la table imbriquée, à traiter comme des données pour alimenter une seconde table. Le nom de celui-ci est influencé par NAME="related" (le nom final contient un suffixe toplevel_related).
- Les définitions de COLUMN dans cet élément <TABLE> font référence aux clés JSON dans le tableau et construisent les champs dans la deuxième table.
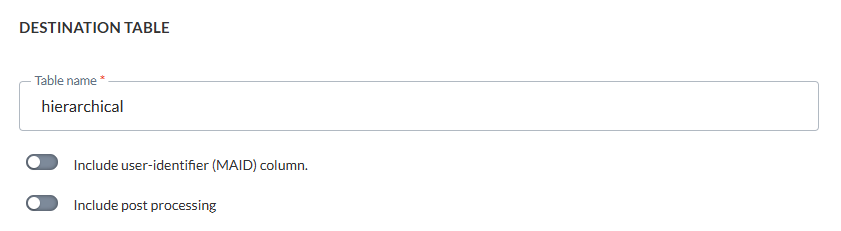
La table intermédiaire choisie est dite 'hierarchical' :
Résultats :
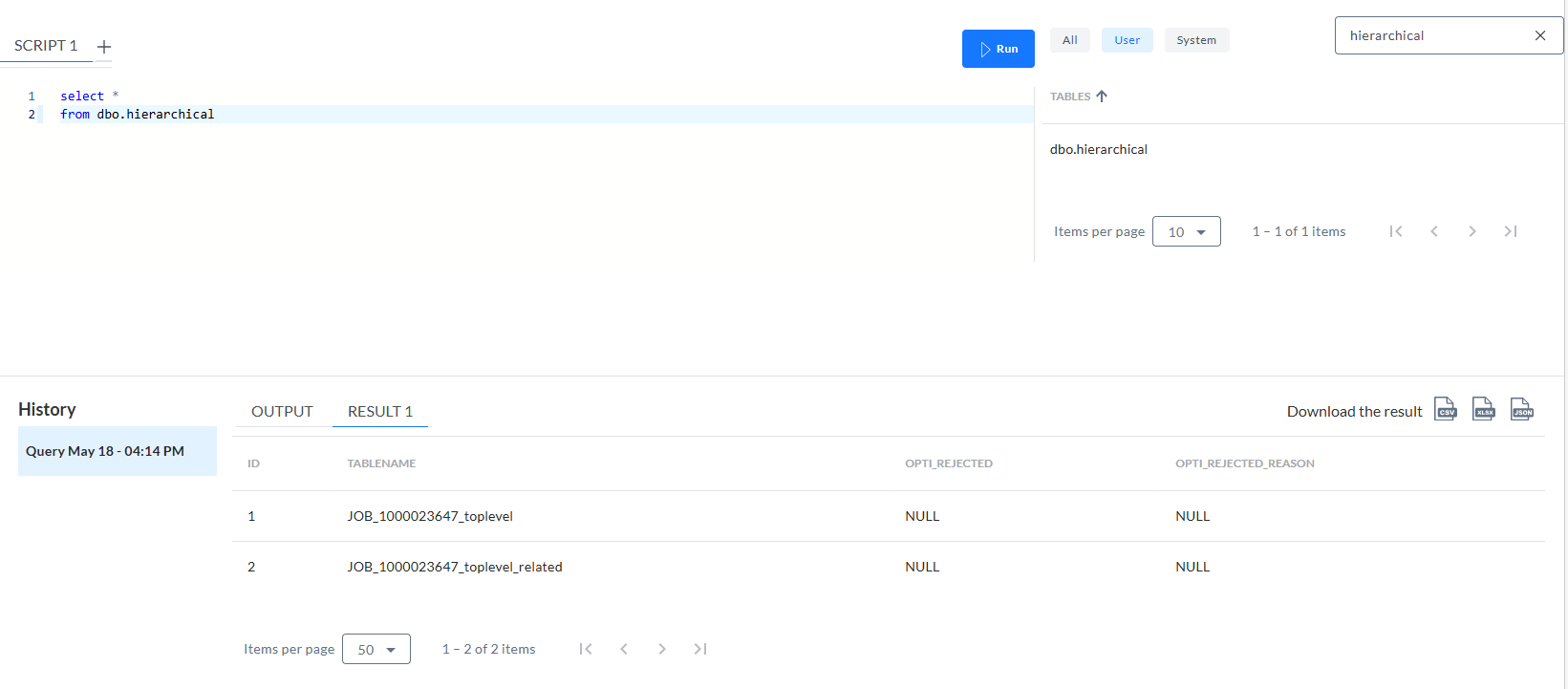
-
Dbo.hierarchical contient deux lignes, affichant les noms des tables :
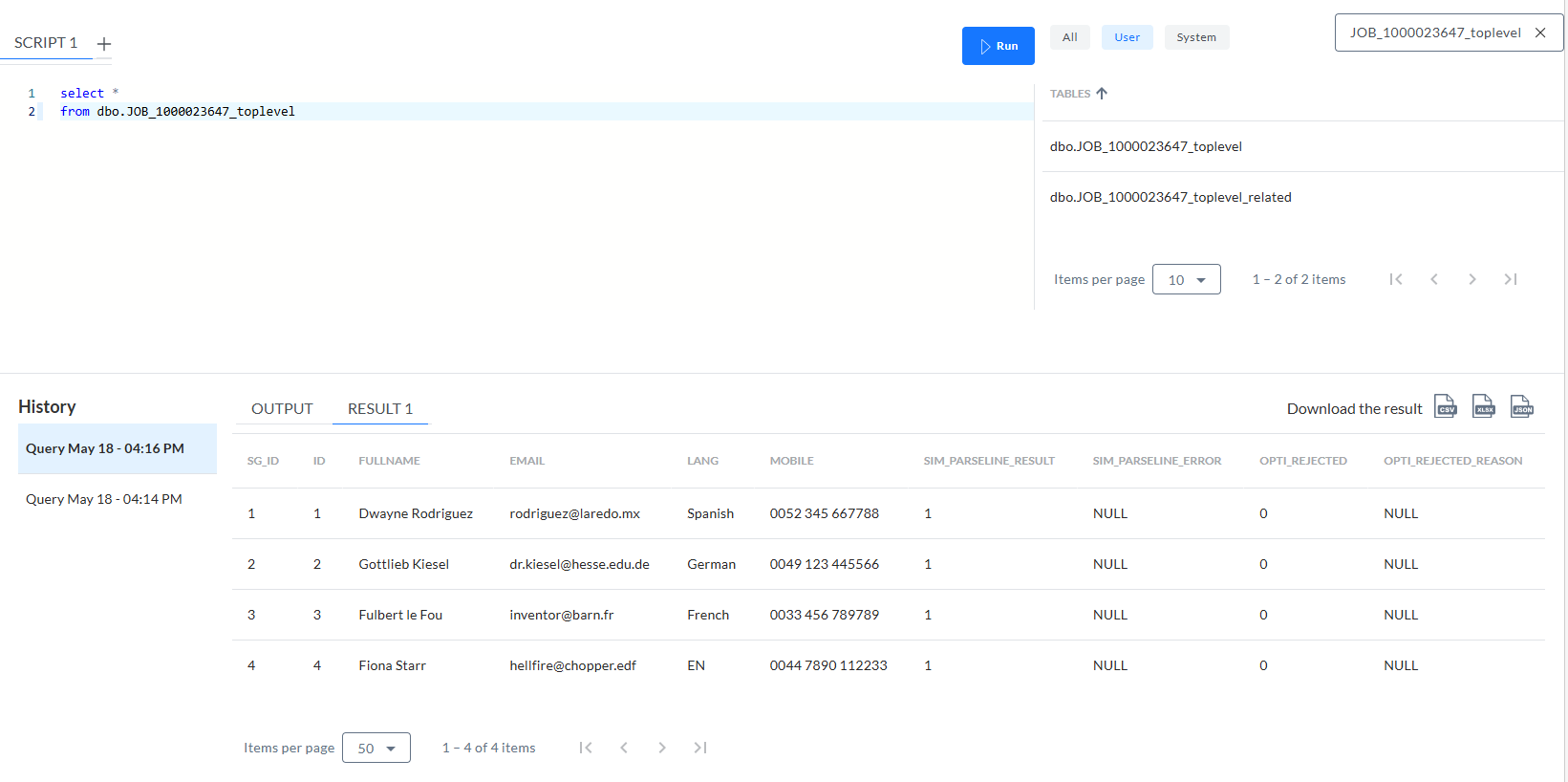
-
JOB_[ID]_toplevel - Table contenant 4 lignes des clés primaires :
-
JOB_[ID]_toplevel_related - Table contenant 7 lignes, où TOPLEVEL_ID est une clé étrangère relative à l'ID de la table précédente :
Campaign
