Les tâches d'importation peuvent être créées de deux manières différentes:
- À partir du menu volant de l'entrée Echange de données, dans la barre de navigation de gauche. Cliquez sur le bouton + Nouveau et sélectionnez le type de tâche souhaité dans la liste déroulante.
- Dans la page de démarrage, cliquez sur + Nouveau > Tâche d'importation. Un assistant vous guide tout au long du processus de création et de configuration de la tâche.

Remarque:L'aperçu des étapes vous permet d'accéder directement à une étape spécifique lorsque vous éditez une tâche.
- Définir les Propriétés générales
- Définir la source
- Facultatif - Définir les dossiers de post-traitement
- Facultatif - Inclure la décompression et le déchiffrement
- Définir la destination
- Afficher l'Historique
Propriétés générales
Cette section vous permet de définir les options de programmation et de notification de la tâche d'importation.
Propriétés
- Chemin du dossier — Définissez le chemin du dossier pour la tâche. Il s'agit de l'emplacement dans la structure de dossier où la tâche est stockée.
- Nom et description — Saisissez le nom et la description de la tâche. Choisissez un nom et une description explicites afin de pouvoir reconnaître facilement votre tâche sur la page de démarrage. Pour faciliter l'identification, il est recommandé d'utiliser un préfixe ou une convention d'appellation qui indique le type de tâche, par exemple : chargement de données, exportation de données, SQL, lot (parallèle) et priorité.
- Libellé de l'actif - Le(s) libellé(s) attribué(s) à cet actif. Sélectionnez un ou plusieurs libellés dans la liste déroulante. (Ces libellés sont créés dans le module Configuration Admin.) Les utilisateurs disposant des autorisations d'accès appropriées peuvent également créer de nouveaux libellés en saisissant leur nouvelle valeur dans le champ.
- Nom de l'API — Ce nom est utilisé lorsque la tâche est exécutée via l'API. Par défaut, le nom de l'API est complété par le nom donné à la tâche.
Programmation
Le commutateur de programmation indique si cette tâche doit avoir sa propre programmation. Cela n'est pas nécessaire si cette tâche fait partie d'une exécution de tâches par lot (travail par lot). Dans ce cas, elle hérite de la programmation du travail par lot parent.
Lorsque cette option est activée, la section Programmation permet de définir la période de validité de la tâche, ainsi que son occurrence d'exécution.
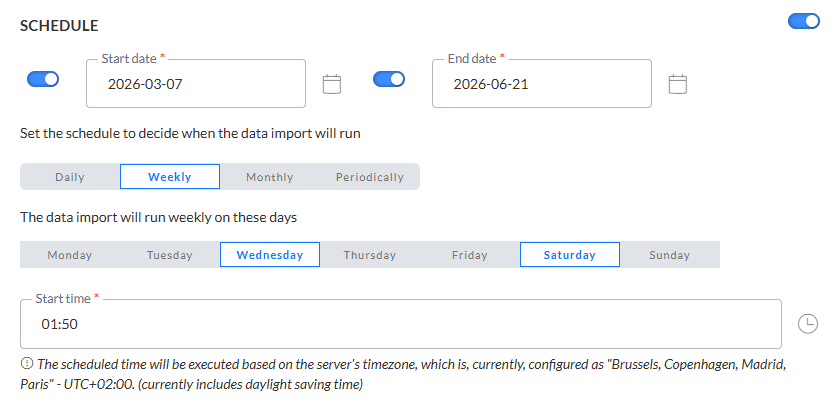
Date de début et de fin — Vous pouvez définir une date de début et/ou une date de fin pour la tâche. Votre tâche peut par exemple commencer tout de suite, mais doit être exécutée indéfiniment.
Périodicité — Permet d'indiquer quand la tâche doit être exécutée:
- Tous les jours — Permet d'indiquer les heures de la journée auxquelles la tâche doit être exécutée. Vous pouvez en sélectionner plusieurs.
- Toutes les semaines — Permet d'indiquer le jour où la tâche doit être exécutée. La tâche peut être exécutée plusieurs fois par semaine. Vous pouvez également définir l'heure de début.
- Tous les mois — Permet de sélectionner les jours du mois auxquels la tâche doit être exécutée. Vous pouvez également sélectionner l'heure de la journée à laquelle la tâche doit être lancée.
- Périodiquement — Permet de définir la récurrence de la tâche, exprimée en minutes. Par exemple, la tâche est exécutée toutes les 10 minutes.
Remarque : L'heure de programmation sera exécutée en fonction du fuseau horaire du serveur. Le fuseau horaire du serveur actuellement configuré est mentionné à côté de l'icône d'information.
Déclencher un Journey après l'exécution d'une tâche

Cette option vous permet si vous le souhaitez de déclencher l'exécution d'un Transactional Journey après l'exécution réussie d'une tâche. Cela signifie que le Journey ne sera pas exécuté si la tâche échoue. L'utilisateur en est alors informé.
Journey de destination — Sélectionnez un Journey de destination dans la liste déroulante. Vous ne pouvez sélectionner que des Transactional Journeys.
Déclencher un Custom Event après l'exécution de la tâche
Cette option vous permet de déclencher l'exécution d'un journey piloté par les événements. Par exemple, après avoir importé des données via une tâche dans la liste des événements personnalisés de la base de données, vous devez déclencher explicitement le journey qui utilise cette liste d'événements personnalisée pour vous assurer que les fiches sont traitées.
Vous devez d'abord sélectionner la liste d'audiences, puis une liste d'événements personnalisés liée. Les listes d'événements personnalisés sélectionnées ne peuvent être utilisées que dans un seul journey à la fois. Elles déclenchent automatiquement ce journey.
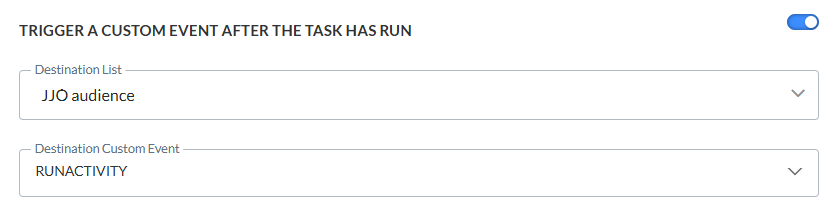
Notifications
Un message peut être envoyé :
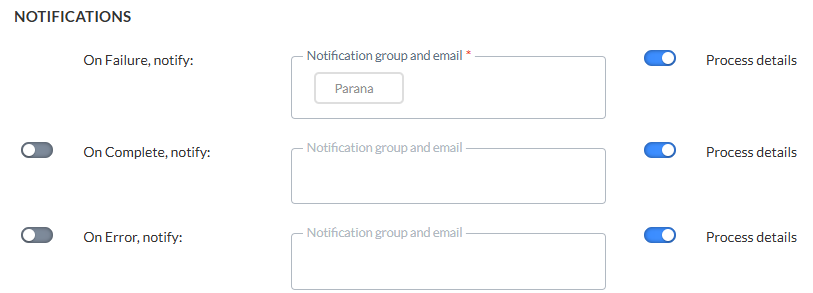
- * OnFailure — Lorsque le processus échoue. Cette situation peut se produire lorsqu'il y a un décalage de données, un décalage de numéro de colonne entre la source et la cible, etc. Au moins un groupe de notifications / une adresse e-mail est obligatoire.
- OnComplete — Lorsque la tâche est terminée avec succès.
- OnError — Lorsque la tâche est terminée avec des erreurs (le travail a été terminé, mais une ou plusieurs tâches ont généré des erreurs/exceptions).
- On No file — Lorsqu'aucun fichier n'a pu être trouvé.
Pour activer cette option, il vous suffit d'activer la case à cocher correspondante et de saisir une ou plusieurs adresses e-mail. (Les adresses e-mail doivent être séparées par un point-virgule.) Vous pouvez également sélectionner un groupe de notifications. Ces groupes de notifications sont créés dans la configuration Administrateur.
Remarque: Les e-mails de notification en cas d'échec de la tâche sont obligatoires. Les autres notifications sont facultatives.
Configurer le planificateur (Optionnel)
Remarque: La section Planificateur n'est visible que si des planificateurs sont configurés sur votre environnement. Par défaut, il y a 1 planificateur, auquel cas cette section n'est pas affichée car ce planificateur par défaut est utilisé. S'il existe plus d'un planificateur configuré, vous avez accès à la section Planificateur.
Lorsque plusieurs tâches, importations ou exportations sont exécutées, il pourrait se révéler judicieux d'utiliser un planificateur différent afin de s'assurer que les tâches dont l'exécution est longue n'interfèrent pas avec les tâches dont l'exécution est plus courte. La configuration d'un planificateur est facultative. Si vous conservez le planificateur par défaut, toutes les tâches/exportations/importations seront exécutées, mais si l'une des tâches est plus longue, la tâche plus courte ne sera exécutée que lorsque cette tâche plus longue sera terminée.

Vous pouvez choisir entre 3 planificateurs différents : le planificateur par défaut, le planificateur personnalisé 1 et le planificateur personnalisé 2. En sélectionnant des planificateurs différents pour vos tâches, ces dernières vont s'exécuter en parallèle, sans interférer l'une avec l'autre. Ce qui signifie que si certaines tâches sont plus longues à exécuter, il pourrait se révéler judicieux de les exécuter sur un planificateur différent.
Lorsque vous avez terminé, appuyez sur Suivant.
Définir la source
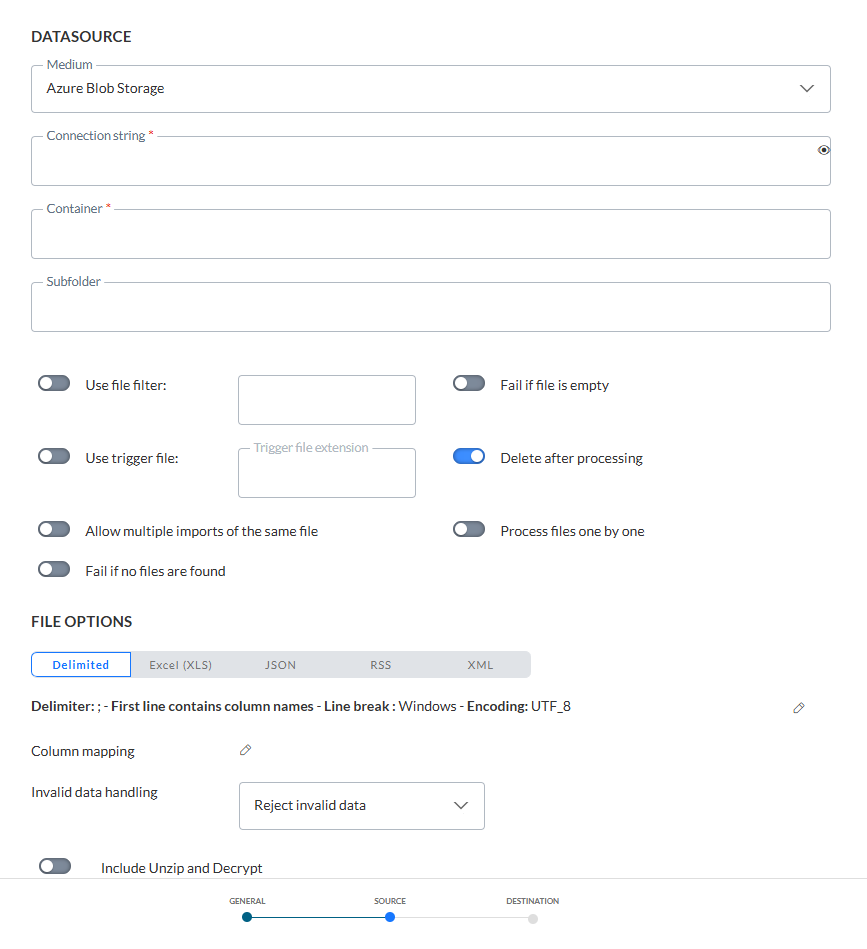
Source de données
Vous pouvez choisir parmi différentes sources de données : Référentiel, URL autorisée, URL publique, Azure Blob Storage, Amazon S3 Storage, Google Cloud Storage, FTPS, SFTP, FTPS implicite. En fonction du moyen sélectionné, différentes options de connexion doivent être configurées:
Référentiel — Le serveur sur lequel la procédure est exécutée contient un système de fichiers local comprenant le dossier Données Campaign. Dans la liste déroulante, sélectionnez le sous-dossier dans lequel récupérer le fichier d'importation. Veuillez noter que lorsque cette option est sélectionnée, vous devez également spécifier le chemin d'accès à l'échange de données.
Remarque: Le référentiel est uniquement disponible pour les clients sur site, car il nécessite la configuration d'un réseau et d'un emplacement de serveur.
URL publique — Fournissez l'URL. Accessible sans informations de connexion ni mot de passe et supportant HTTP ou HTTPS.
URL autorisée — Saisissez l'URL et le nom d'utilisateur, ainsi que le mot de passe permettant de s'y connecter. Ne prend en charge que le protocole HTTPS.
Azure Blob Storage — Saisissez la chaîne de connexion (vous pouvez activer ou désactiver l’affichage de la chaîne en cliquant sur l’icône Œil) et le conteneur, ainsi qu’un sous-dossier facultatif. (*)
Amazon S3 Storage — Saisissez l’ID de la clé d’accès et la clé d’accès secrète (vous pouvez activer ou désactiver l’affichage des deux chaînes en cliquant sur l’icône Œil), le nom du compartiment, le code du point de terminaison de la région et un sous-dossier facultatif. (*)
Google Cloud Storage — Saisissez le type, l’ID projet, l’ID de la clé privée et la clé privée (vous pouvez activer ou désactiver l’affichage des deux chaînes en cliquant sur l’icône Œil), l’e-mail client, l’ID client, l’URI d'authentification, l’URI du token, l’URL du certificat X509 du fournisseur d'authentification, l’URL du certificat X509 du client, le nom du compartiment et un sous-dossier facultatif. (*)
* Remarque : Vous trouverez ici des détails sur la façon de configurer le stockage dans le Cloud.
Prédéfini — Lorsque vous sélectionnez cette option, le champ 'Moyen de transport prédéfini' s'affiche et vous permet de sélectionner un média dans une liste de médias prédéfinis. Ces médias sont déjà configurés dans le module Admin Configuration et liés à votre Unité commerciale. Lorsque vous en sélectionnez un, tous les paramètres correspondants sont utilisés. Vous pouvez sélectionner une sous-dossier dans la liste déroulante des tâches.
FTPS, FTPS implicite, SFTP — Indiquez le nom du serveur, ainsi que le nom d'utilisateur et le mot de passe permettant de se connecter au serveur. Vous avez la possibilité de sélectionner un sous-dossier sur le serveur (un sous-dossier est sélectionné par défaut). FTPS est l'option recommandée en raison de la couche de sécurité supplémentaire contenue dans le protocole.
SFTP peut être fourni par Zeta ou sur une plate-forme externe.
Seules les IP se connectant sur le port 22 par défaut ont besoin d'une liste blanche.
Authentification par clé privée
Pour SFTP, outre l'utilisation d'un mot de passe pour s'authentifier lors de la connexion au serveur, il est possible d'utiliser une clé privée:
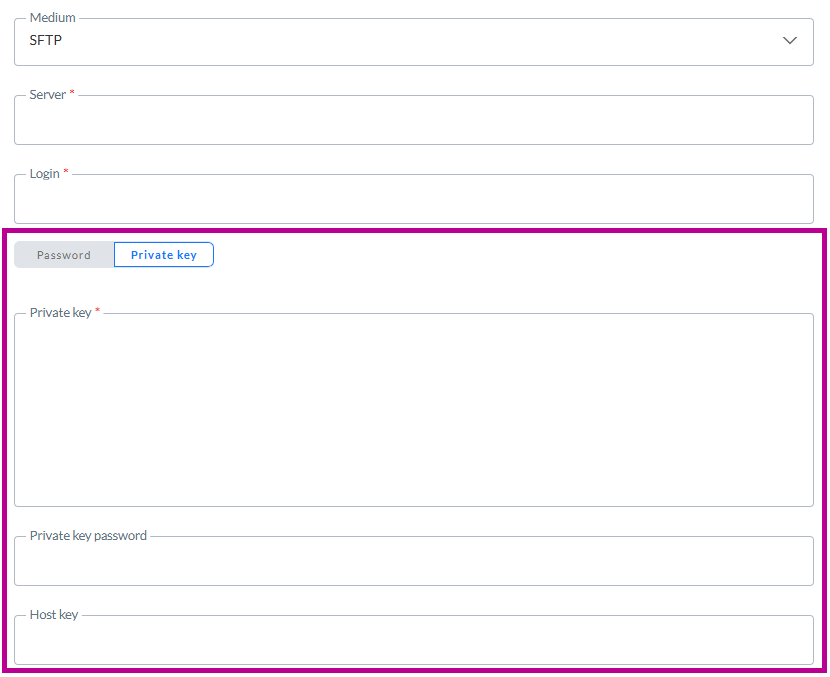
Un curseur permet de choisir entre Mot de passe et Clé privée.
Lorsque l'option Clé privée est sélectionnée, vous pouvez saisir (ou coller) les données de la clé privée dans le champ Clé privée.
Si la clé privée requiert un mot de passe (comme c'est le cas sur certains serveurs), vous pouvez saisir le mot de passe dans le champ Mot de passe de la clé privée . Ce champ est facultatif.
Remarque: Les données des deux champs (clé privée et mot de passe de la clé privée) sont cryptées et stockées dans la base de données et ne sont utilisées que lors du transfert des fichiers.
La clé d'hôte est un champ facultatif qui peut être utilisé comme étape de vérification supplémentaire pour s'assurer que vous vous connectez au bon serveur.
Remarque:
Lors de l'enregistrement de la [Tâche d'importation/Importation de données/Tâche d'exportation/Exportation de données/Emplacement] :
- Le contenu du champ de la clé privée est vidé (pour des raisons de sécurité).
- L'intitulé du champ Clé privée est mis à jour et devient Spécifier une nouvelle clé privée pour mettre à jour la clé privée existante.
- Le contenu du champ Mot de passe de la clé privée est vidé (pour des raisons de sécurité).
- L'intitulé du champ Mot de passe de la clé privée est mis à jour et devient Spécifier un nouveau mot de passe de la clé privée pour mettre à jour le mot de passe de la clé privée existante.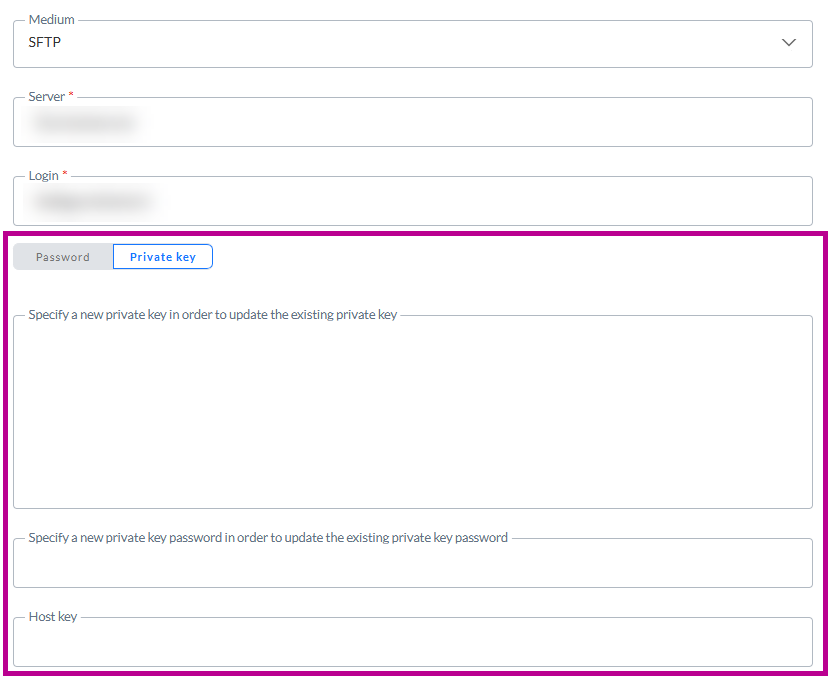
Remarque: En raison de la sécurité interne mise en place dans l'environnement SAAS, les transferts FTP vers et depuis des serveurs externes ne sont autorisés que sur les ports FTP par défaut.
Remarque: Si vous n'avez pas le droit de définir d'emplacements, la section Emplacement ne sera lue que lors de l'édition de la tâche. Lors de la création d'une nouvelle tâche, seul un emplacement prédéfini peut être sélectionné.
L'emplacement du fichier ci-dessus est suivi de plusieurs options supplémentaires:
Utiliser un filtre de fichiers — Permet de filtrer les fichiers à importer. Le filtre de masque de fichier utilise les valeurs spécifiées en tant que modèle de recherche. Seuls les noms de fichiers correspondant au modèle sont choisis. Vous pouvez par exemple saisir les extensions des fichiers qui doivent être importés. Vous pouvez utiliser * comme caractère générique et même générer des champs de personnalisation tels que la date actuelle.
Échec si le fichier est vide — Permet de définir si l'importation doit échouer si le fichier est vide.
Utiliser un fichier déclencheur — Vous pouvez utiliser un fichier déclencheur. Cochez l'option et saisissez l'extension du fichier. La principale fonction d'un fichier de déclenchement est de vérifier si le fichier de données principal a déjà été entièrement téléchargé. Il peut arriver qu'un chargeur de données récupère un fichier alors qu'il est encore en train d'être transféré vers l'emplacement. Le fichier déclencheur, toutefois beaucoup plus petit, est créé juste après la fin du transfert. Ainsi, la charge de données sait avec certitude quand le fichier peut être traité.
Remarque: Le fichier déclencheur porte le même nom que le fichier d'importation, mais son extension est différente.
Supprimer après traitement — Cochez cette option si le fichier peut être supprimé après le chargement. Cette option est généralement utilisée lors de l'utilisation de noms de fichiers dynamiques. Si vous utilisez des noms de fichiers dynamiques, vous pouvez activer cette option. Si ce n'est pas le cas, soit le chargement de données échouera (si l'option « Autoriser plusieurs importations du même nom de fichier » est activée), soit chaque fichier sera récupéré et traité à chaque intervalle. Cette solution est toutefois à éviter. Si vous n'activez pas l'option « Supprimer le fichier après le traitement » et que le fichier n'est pas écrasé avant chaque intervalle d'exécution, vous finirez par écraser toutes les fiches avec les « anciennes » données d'un fichier d'importation précédent.
Autoriser plusieurs importations du même nom de fichier— Un fichier d'importation peut être téléchargé plusieurs fois; la liste des fichiers téléchargés est conservée au fil du temps. Si cette option n'est pas cochée, l'importation d'un fichier portant le même nom n'est pas autorisée le même jour.
Remarque: Cependant, pour pouvoir suivre et consigner les multiples chargements de données, il est conseillé de toujours activer cette option. Avec un nom de fichier unique, il est possible d'obtenir plus d'informations.
Échec si aucun fichier n'est trouvé — Permet de définir si le chargement doit échouer si aucun fichier correspondant au filtre de fichiers n'est trouvé. Utilisez cette option si l'importation nécessite un fichier à traiter à l'intervalle défini.
Traiter les fichiers l'un après l'autre — Si cette option est cochée, tous les fichiers sont traités les uns après les autres tout au long du processus (du téléchargement au traitement et enfin au transfert du fichier sur le serveur). En cas de problème avec l'un des fichiers, les autres fichiers seront tout de même traités. Lorsque l'option est décochée, la poursuite du traitement est interrompue lorsqu'un problème survient dans l'un des fichiers.
Options de fichier
Les cinq types de fichiers suivants sont disponibles :
- Délimité — Fichiers utilisant une virgule, un point-virgule, un barre verticale ou une tabulation comme délimiteur de colonnes.
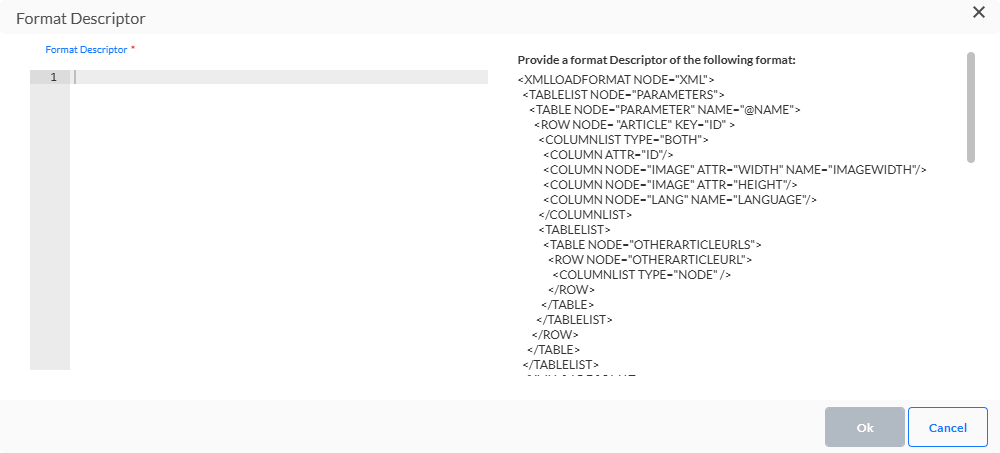
- XML — Le fichier XML entrant doit être analysé. Le descripteur de format XML permet de définir les tables et les champs qui doivent être séparés du fichier XML. (note technique sur l'analyse XML)
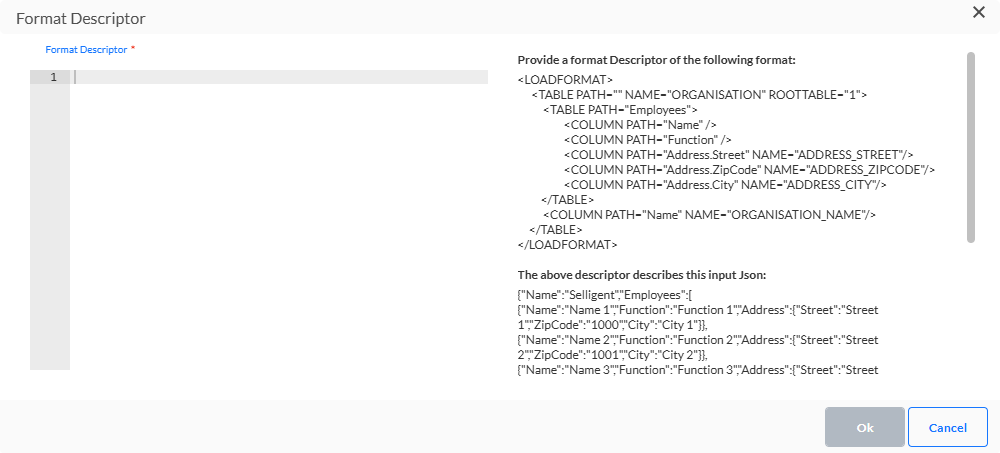
- JSON — Le JSON entrant doit être analysé. Le descripteur de format JSON permet de définir les tables et les champs qui doivent être séparés du fichier JSON.
- Excel — Un fichier Excel avec ou sans en-tête de ligne peut être utilisé comme fichier d'importation. XLS et XLSX peuvent être utilisés. Lorsque plusieurs feuilles sont disponibles dans le XLS, seule celle sélectionnée sera importée.
- RSS — Le nœud racine du fichier RSS doit être fourni.
Delimited

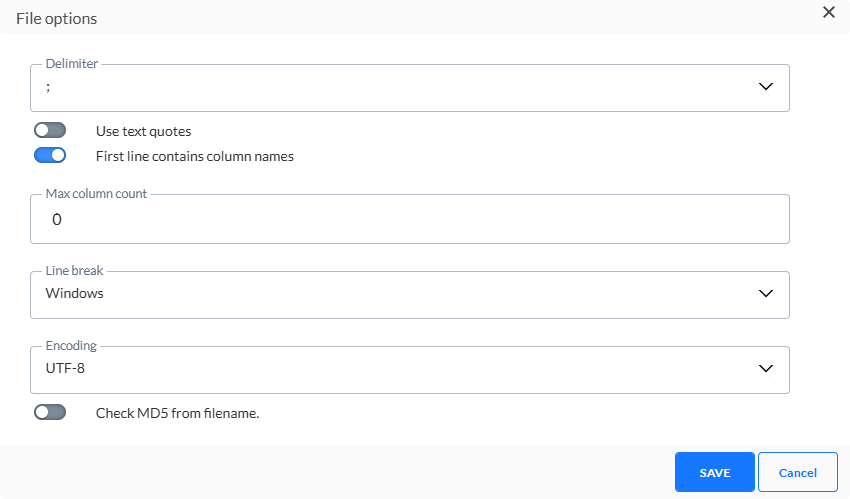
Délimiteur — Permet de définir le délimiteur du fichier. Vous pouvez choisir entre Tabulation, Virgule, Point-virgule et Barre verticale. Le ; est sélectionné par défaut.
Utiliser des guillemets — Il est possible de mettre le texte entre guillemets doubles. Si tel est le cas, toutes les données alphanumériques sont incluses dans les guillemets et garantissent qu'un champ contenant le caractère délimiteur ne sera pas interprété comme une colonne supplémentaire.
Exemple: Dans un fichier séparé par des barres verticales ;
ma couleur|préférée : indique qu'il y a deux champs, mais en plaçant les guillemets en tête et en fin de texte, on considère qu'il s'agit d'un seul champ « ma couleur|préférée ».
La première ligne contient les noms des colonnes — Vous pouvez également définir la première ligne comme celle contenant les noms de colonne. Cette option sélectionnée par défaut est recommandée, car les noms de colonne du fichier sont traduits dans les en-têtes de colonne de votre tableau.
Remarque: Lorsqu'un fichier contient la ligne d'en-tête avec les noms des colonnes, mais aucune donnée, il ne s'agit pas d'un fichier vide, mais d'un fichier valide sans fiches. Par conséquent, il est traité sans erreur.
Nombre max de colonnes — Le nombre maximum de colonnes autorisé dans le fichier. En raison de la nature dynamique de la tâche de chargement de données, alors que la table de préparation s'adapte automatiquement au contenu du fichier plat, il peut être utile de fixer une limite supérieure pour les colonnes qui peuvent être créées.
Saut de ligne — Permet de définir le Saut de ligne sur Windows ou Unix. Windows utilise le retour chariot et le saut de ligne ("\r\n") en fin de ligne, où Unix utilise uniquement le saut de ligne ("\n").
Encodage — Permet de définir le type d'encodage à appliquer au fichier. Cliquez sur la liste déroulante pour accéder à la liste étendue des mécanismes d'encodage.
Vérifier MD5 à partir du nom du fichier — Cette option permet de revérifier le contenu du fichier. Cette clé MD5 est ajoutée au nom du fichier et est créée sur la base du contenu du fichier. Si cette option est activée, la clé MD5 est vérifiée par rapport au contenu du fichier et active la détection de modifications dans le fichier.
XML

Encodage — Permet de définir le type d'encodage à appliquer au fichier. Cliquez sur l'icône en forme de crayon pour accéder à une boîte de dialogue et à une liste complète de mécanismes d'encodage. De plus, l'option Vérifier MD5 à partir du nom du fichier est utilisée pour vérifier le contenu du fichier. Cette clé MD5 est ajoutée au nom du fichier et est créée sur la base du contenu du fichier. Si cette option est activée, la clé MD5 est vérifiée par rapport au contenu du fichier et active la détection de modifications dans le fichier.
JSON
Encodage — Permet de définir le type d'encodage à appliquer au fichier. Cliquez sur l'icône en forme de crayon pour accéder à une boîte de dialogue et à une liste complète de mécanismes d'encodage. De plus, l'option Vérifier MD5 à partir du nom du fichier est utilisée pour vérifier le contenu du fichier. Cette clé MD5 est ajoutée au nom du fichier et est créée sur la base du contenu du fichier. Si cette option est activée, la clé MD5 est vérifiée par rapport au contenu du fichier et active la détection de modifications dans le fichier.
Excel

Nom de feuille — Le nom de la feuille dans le fichier xls faisant l'objet de l'importation. Lorsqu'il y a plusieurs feuilles de calcul, seule la feuille de calcul nommée est traitée, toutes les autres feuilles de calcul sont ignorées. S'il y a plusieurs feuilles de calcul à traiter, elles doivent être traitées comme des fichiers XLSX individuels, car une seule feuille de calcul peut être importée à la fois
La première ligne contient les noms de colonnes — Sélectionnez l'option si la ligne supérieure de votre feuille contient les noms de colonnes.
Lignes à passer — Indiquez le nombre de lignes du fichier à exclure.
Encodage — Permet de définir le type d'encodage à appliquer au fichier. À partir du menu déroulant, vous avez accès à une liste complète de mécanismes de codage. De plus, l'option Vérifier MD5 à partir du nom du fichier est utilisée pour vérifier le contenu du fichier. Cette clé MD5 est ajoutée au nom du fichier et est créée sur la base du contenu du fichier. Si cette option est activée, la clé MD5 est vérifiée par rapport au contenu du fichier et active la détection de modifications dans le fichier.
RSS

Nœud racine (facultatif) — Le nœud racine desquels tous les nœuds enfants sont récupérés. Si le nœud racine n'est pas configuré, le Xpath par défaut dans lequel les données sont attendues est le nœud Channel. Si le nœud racine est configuré, vous pouvez utiliser ce nom.
Remarque : Tous les éléments <item> et leur contenu à l'intérieur du nœud racine (par exemple, <channel>) peuvent être importés.
Si d'autres éléments apparaissent directement sous l'élément racine (au même niveau que les éléments <item>), ils ne seront pas importés.
Exemple 1 — Si nous ne configurons pas de nœud racine, le nœud 'channel' de ce fichier RSS sera utilisé comme racine par défaut (l'article et ses détails seront importés) :
<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<item>
<title>News of today</title>
<link>https://www.xul.fr/en-xml-rss.html</link>
<description>RSS item 1</description>
<name>Siyashree</name>
</item>
</channel>
</rss>Exemple 2 — Si nous configurons un élément "customrss" comme nœud racine, il sera utilisé comme racine dans le fichier RSS suivant (l'article et ses détails seront importés) :
<?xml version="1.0" ?>
<rss version="2.0">
<customrss>
<item>
<title>News of today</title>
<link>https://www.xul.fr/en-xml-rss.html</link>
<description>RSS item 1</description>
<name>Siyashree</name>
</item>
</customrss>
</rss>Encodage — Définit le type de codage à appliquer au fichier. Cliquez sur la liste déroulante pour accéder à la liste étendue des mécanismes d'encodage.
Vérifier MD5 à partir du nom du fichier — Cette option permet de revérifier le contenu du fichier. Cette clé MD5 est ajoutée au nom du fichier et est créée sur la base du contenu du fichier. Si cette option est activée, la clé MD5 est vérifiée par rapport au contenu du fichier et active la détection de modifications dans le fichier.
Remarque : Lors de l'utilisation de fichiers RSS, Media RSS* est pris en charge par défaut.
* Qu'est-ce que Media RSS ? Il s'agit d'une extension RSS qui apporte plusieurs améliorations aux annexes RSS et qui est utilisée pour la syndication de fichiers multimédias dans les flux RSS. Elle a été conçue à l'origine par Yahoo! et la communauté Media RSS en 2004, mais en 2009, son développement a été confié au RSS Advisory Board.
Veuillez consulter https://www.rssboard.org/media-rss pour plus d'informations.
Exemple de fichier RSS contenant des médias :
<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<item>
<title>The latest video from an artist</title>
<link>http://www.foo.com/item1.htm</link>
<media:content url="http://www.foo.com/movie.mov" fileSize="12216320" type="video/quicktime" expression="full">
<media:player url="http://www.foo.com/player?id=1111" height="200" width="400" />
<media:hash algo="md5">dfdec888b72151965a34b4b59031290a</media:hash>
<media:credit role="producer">producer's name</media:credit>
<media:credit role="artist">artist's name</media:credit>
<media:category scheme="http://blah.com/scheme">
music/artistname/album/song
</media:category>
<media:text type="plain">
Some text
</media:text>
<media:rating>nonadult</media:rating>
<dcterms:valid>
start=2002-10-13T09:00+01:00;
end=2002-10-17T17:00+01:00;
scheme=W3C-DTF
</dcterms:valid>
</media:content>
</item>
</channel>
</rss>
Mise en correspondance des colonnes
La mise en correspondance des colonnes vous permet d'établir la correspondance des colonnes de la base de données avec les colonnes du fichier d'importation. La mise en correspondance des colonnes définit la structure du fichier attendu. Des champs peuvent être ajoutés manuellement avec un nom, un type et une longueur.
Remarque technique : L'ajout du mappage des colonnes devient vital pour créer des chargements de données réussis. Par conséquent, si aucune configuration n'est définie pour les colonnes, des avertissements sont lancés. Si aucun mappage de colonne n'est défini, toutes les colonnes des tables de préparation ciblées seront de type NVARCHAR(MAX). Ce type de données présente des inconvénients importants, c'est pourquoi l'ajout d'un mappage de colonnes doit être considéré comme obligatoire pour s'assurer des points suivants :
- Vous pouvez éviter les conversions implicites lors de la migration des données de la table de préparation vers la table de production. Les types de données sont déjà définis correctement avec la bonne configuration de mappage de colonne activée et ils devraient correspondre au type de données de la base de données de production.
- Vous ne prendrez que la quantité minimale de stockage nécessaire en stockant ces données dans la table de préparation. N'oubliez pas que pour chaque caractère Unicode ou n(var)char, vous aurez besoin de deux octets. Ce type de données entraîne des opérations de lecture massives qui peuvent être évitées en utilisant des types de données plus appropriés. Ce dernier point est particulièrement vrai lorsque les valeurs clés, sur lesquelles l'UPSERT de votre procédure stockée de chargement de donnée est basé, sont du type nchar.
- Vous pouvez créer des index. Il est impossible de placer des index sur des champs dont la somme totale de la longueur du type de données * dépasse les 900 octets. Par conséquent, placer des index sur NVARCHAR(MAX) n'est tout simplement pas possible au niveau de la base de données.
- Même sans les avantages au niveau de la base de données, les gains de performance sont nombreux avec la mise en œuvre du mappage de colonnes. Évidemment, puisque les types de données finaux sont connus, un plus grand nombre de fiches peuvent être chargées en mémoire à partir du fichier plat et être transférées vers la base de données en même temps.
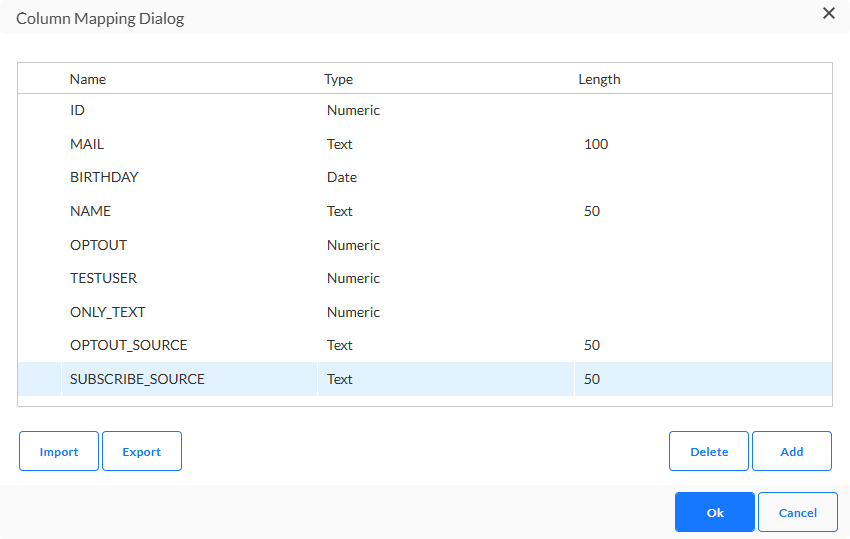
Cliquez sur le bouton Exporter pour exporter la mise en correspondance actuellement définie dans un fichier CSV. Cliquez sur le bouton Importer pour importer un fichier CSV existant et utiliser la structure du fichier pour la mise en correspondance.
Options supplémentaires
Gestion des données non valides — Permet de définir ce qui doit être fait s'il y a des données non valides. Il s'agit principalement de questions relatives aux délimiteurs et aux types de données. Vous pouvez choisir l'une des options suivantes:
- Rejeter les données non valides — marque les fiches non valides comme rejetées. Tout le contenu d'une ligne du fichier source est placé dans un fichier de rejet avec une description de l'erreur.
- Passer les données non valides — continue sans agir sur les données non valides. Il est possible que certaines lignes ne soient pas admissibles à l'importation en raison de problèmes tels que : des délimiteurs de montants erronés, des types de données erronés, des erreurs de troncature, etc. Si vous activez cette option, vous ignorerez ces fiches dans le fichier plat et passerez à la suivante. Nous vous conseillons, si vous choisissez d'activer cette option, de toujours l'utiliser conjointement avec les fonctionnalités suivantes.
- Conserver les données non valides — stocke les données dans la table de pré-production. Cependant, les données originales seront stockées dans un seul champ (sous forme de texte) au lieu de remplir les champs obligatoires de la table de préparation. La manière dont ces données sont traitées vous appartient.
- Arrêter le traitement — arrête complètement le processus et génère une erreur
Utiliser les dossiers de traitement — Si cette option est cochée, vous disposerez d'un plus grand contrôle sur ce qui se passe au cours du traitement et pourrez le vérifier de manière plus précise. Cette option est uniquement disponible pour les sources externes de données serveur de fichier (FTP). Lorsque cette option est cochée, une étape supplémentaire vient s'ajouter dans l'assistant.
Pendant leur traitement, les fichiers sont placés dans le dossier de traitement. Une fois le traitement terminé, ils sont placés dans le dossier Terminé. Si un problème a été rencontré, les fichiers seront enregistrés dans le dossier Échec. Ces dossiers sont situés sur le serveur (S)FTP(S).
Inclure la décompression et le déchiffrement — Activez cette option si le fichier d'importation doit être décompressé et déchiffré. Une étape supplémentaire vient alors s'ajouter dans l'assistant.
Dossiers
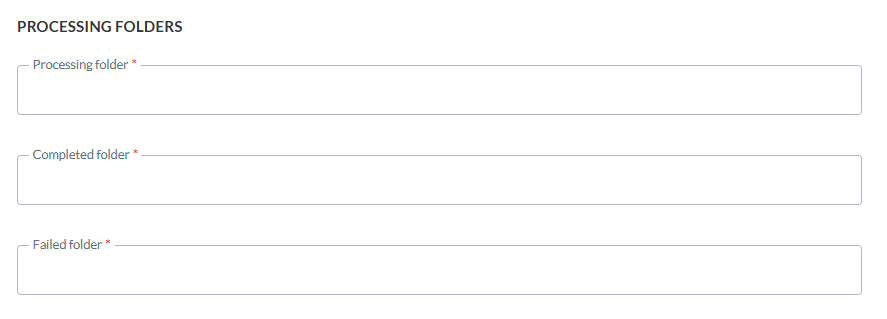
Cette section vous permet de définir les dossiers qui doivent être utilisés sur le serveur:
Dossier de traitement — Dossier utilisé avant le traitement du fichier
Dossier terminé — Dossiers utilisés lorsque le traitement du fichier a réussi
Dossier Échec — Dossier utilisé lorsque le traitement a échoué
Décompresser et déchiffrer
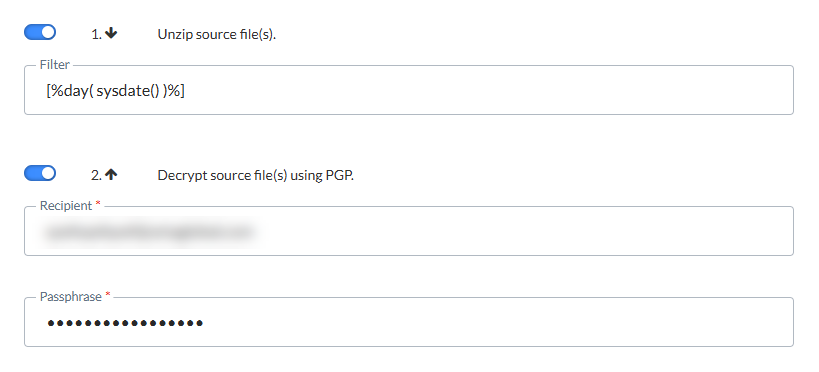
Sélectionnez les options qui doivent être exécutées et l'ordre dans lequel elles doivent l'être. Cliquez sur la flèche pour inverser l'ordre.
Décompresser les fichiers sources — Si le fichier source est compressé, activez l'option permettant premièrement de décompresser les fichiers. Le champ 'Filtre' vous permet de filtrer les fichiers. Le filtre peut contenir des expressions. Cliquez sur l'élément de personnalisation du champ Filtre pour accéder à la boîte de dialogue et sélectionner l'expression.
Remarque importante : Le fichier .zip doit correspondre au masque de fichier qui a été spécifié dans le filtre de fichier de l'onglet Source.
Les expressions suivantes sont prises en charge:
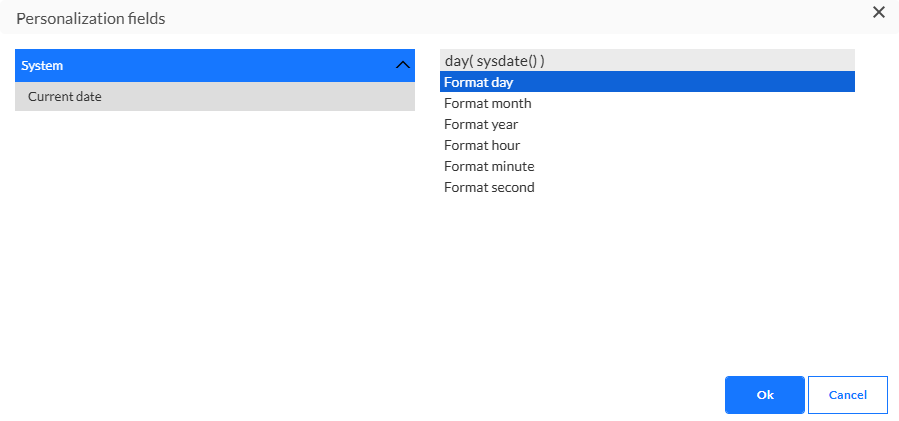
- [%year(sysdate())%]
- [%month(sysdate())%]
- [%day(sysdate())%]
- [%hour(sysdate())%]
- [%minute(sysdate())%]
- [%second(sysdate())%]
Décrypter le fichier source à l'aide de PGP— Si le fichier source est crypté avec PGP, l'utilisateur doit saisir la phrase secrète et le destinataire. Le destinataire est en réalité une adresse e-mail, utilisée pour récupérer la clé publique. La phrase secrète est utilisée comme mot de passe pour décrypter les données.
Note technique :
Pour envoyer un fichier crypté depuis un emplacement externe vers la plate-forme Selligent by Zeta:
1. Cryptez le fichier en utilisant la clé publique fournie par Selligent by Zeta.
2. Téléchargez le fichier vers le serveur Selligent by Zeta (S)FTP(S).
3. Configurez une tâche d'importation pour importer ce fichier dans la plate-forme Selligent by Zeta.
- Dans les options Source de cette tâche, activez l'option Inclure la décompression et le déchiffrement.
- Dans l'étape suivante, remplissez les champs Destinataire et Phrase de passe avec les valeurs liées à votre clé PGP Selligent by Zeta pour décrypter le fichier.
Définir la destination
Dans cette section, l'utilisateur définit la destination du fichier importé. Vous devez définir un nom de table de préparation temporaire.
Remarque : Il s'agit du nom d'une table temporaire utilisée pour télécharger des données à partir de la source. Avec le traitement de chaque fichier, cette table sera supprimée et recréée. Gardez cela à l'esprit lorsque vous utilisez des index, des contraintes ou d'autres éléments de cette table.
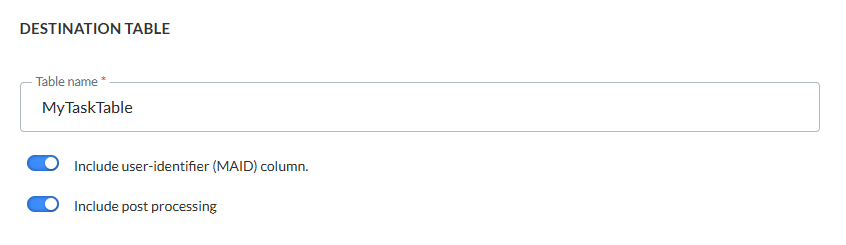
Inclure la colonne identifiant utilisateur (MAID) — Cochez cette option pour inclure une colonne 'MAID' si l'importation est répétée. Si la case à cocher est activée, une colonne 'MAID' supplémentaire est ajoutée à la table créée par l'agent Tâche. Il s'agit d'une façon pratique de mettre à jour les fiches dans la table principale avec les fiches correspondants de la table temporaire, cette dernière étant utilisée comme champ clé pour une mise à jour ou une insertion.
Inclure le post-traitement — Si cette option est cochée, vous avez la possibilité d'effectuer divers traitements de données supplémentaires, ainsi que de traiter la Gestion des rejets. Une étape supplémentaire est ajoutée à l'assistant. Elle vous permet de configurer ces options supplémentaires.
Post-traitement
Traitement des données

Si le traitement des données est requis, activez l'option.
Cliquez sur le bouton Éditer pour sélectionner la Procédure stockée. La boîte de dialogue suivante s'affiche :
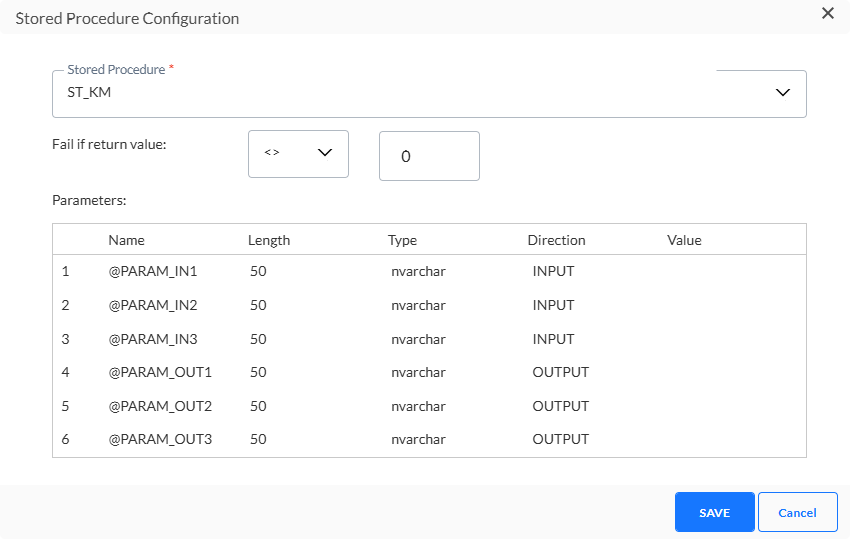
1. Dans la liste déroulante, sélectionnez la Procédure stockée utilisée pour remplir le fichier déclencheur. Il ne doit pas obligatoirement s'agir de la même Procédure stockée que pour le fichier d'exportation.
2. Définissez ensuite l'échec de la contrainte. Utilisez la valeur renvoyée par la Procédure stockée pourdéfinir si elle a ou non échoué.
-
Si aucune valeur de retour explicite n'est définie dans la conception de la procédure stockée, la valeur 0 est renvoyée par défaut en cas de succès. Toute autre valeur renvoyée implique un échec.
Dans ce cas, vous devez définir la contrainte d'échec sur : Échec si valeur de retour <> 0.
-
Lorsque la conception de la procédure stockée contient une ou plusieurs valeurs de retour personnalisées, les valeurs qui sont renvoyées en cas de succès et d'échec dépendent de cette conception.
Dans ce cas, vous devez décider ce que vous considérez être une contrainte d'échec.Exemple 1:
La procédure stockée utilisée définit que la valeur 10 est renvoyée après l'exécution de certaines instructions SQL, et que la valeur 12 est renvoyée après l'exécution d'un autre ensemble d'instructions SQL.
Vous considérez que la partie qui définit la valeur de retour comme étant 12 est la seule qui a réussi. Tous les autres cas doivent être considérés comme des échecs.
ans ce cas, vous définissez la contrainte d'échec sur : Échec si valeur de retour <> 12.Exemple 2:
La procédure stockée utilisée définit les valeurs de retour 1, 10, 50, 51, 52, 53, 54, 55, 56, 60.
Vous considérez les valeurs de retour 1, 10 et 50 comme des valeurs de « réussite ». Les autres valeurs indiquent une erreur et sont donc considérées comme des échecs.
Dans ce cas, vous pouvez définir la contrainte d'échec sur : Échec si valeur de retour >= 51.
3. Paramètres — Certaines Procédures stockées requièrent des paramètres. Le cas échéant, une section supplémentaire est disponible afin de vous permettre de définir ces paramètres.
Cliquez sur le bouton Enregistrer pour stocker la procédure sélectionnée.
Gestion des rejets
La Gestion des rejets est utilisée lorsque la source de données doit être validée. Toutes les fiches qui ne sont pas valides sont exportées dans un fichier séparé.

Concept de base:
- Les données sont transférées dans une table temporaire.
- Deux colonnes supplémentaires sont ajoutées dans la table temporaire (OPTI_REJECTED et OPTI_REJECTED_REASON).
- La Procédure stockée effectue des vérifications des données. Si certains enregistrements contiennent des informations corrompues, la colonne OPTI_REJECTED doit être définie sur '1', ce qui signifie que l'enregistrement est rejeté. Un message de rejet personnalisé peut être défini dans le champ OPTI_REJECTED_REASON.
Ensuite, la Procédure stockée transfère toutes les données valides depuis la table temporaire vers la table Selligent by Zeta.
La liste des emplacements possibles comprend : Référentiel, URL publique, Azure Blob Storage, Amazon S3 Storage, Google Cloud Storage, FTP, SFTP, FTPS, URL autorisée. Les paramètres à compléter dépendent du type d’emplacement sélectionné. L'utilisateur peut sélectionner un sous-dossier pour enregistrer le fichier. Le type de fichier est séparé par défaut par ;.
Référentiel — Le serveur sur lequel la procédure est effectuée contient un système de fichiers local comprenant déjà deux dossiers: Data In et Données Campaign. Vous pouvez sélectionner un sous-dossier dans lequel récupérer le fichier d'importation.
URL publique — Saisissez l'URL. Accessible sans informations de connexion ni mot de passe et supportant HTTP ou HTTPS.
URL autorisée — Saisissez l'URL et le nom d'utilisateur, ainsi que le mot de passe permettant de s'y connecter. Ne prend en charge que le protocole HTTPS.
Azure Blob Storage — Saisissez la chaîne de connexion (vous pouvez activer ou désactiver l’affichage de la chaîne en cliquant sur l’icône Œil) et le conteneur, ainsi qu’un sous-dossier facultatif. (*)
Amazon S3 Storage — Saisissez l’ID de la clé d’accès et la clé d’accès secrète (vous pouvez activer ou désactiver l’affichage des deux chaînes en cliquant sur l’icône Œil), le nom du compartiment, le code du point de terminaison de la région et un sous-dossier facultatif. (*)
Google Cloud Storage — Saisissez le type, l’ID projet, l’ID de la clé privée et la clé privée (vous pouvez activer ou désactiver l’affichage des deux chaînes en cliquant sur l’icône Œil), l’e-mail client, l’ID client, l’URI d'authentification, l’URI du token, l’URL du certificat X509 du fournisseur d'authentification, l’URL du certificat X509 du client, le nom du compartiment et un sous-dossier facultatif. (*)
* Remarque : Vous trouverez ici des détails sur la façon de configurer le stockage dans le Cloud.
Prédéfini — Lorsque vous sélectionnez cette option, le champ 'Moyen de transport prédéfini' s'affiche et vous permet de sélectionner un média dans une liste de médias prédéfinis. Ces médias sont déjà configurés dans le module Admin Configuration et liés à votre Unité commerciale. Lorsque vous en sélectionnez un, tous les paramètres correspondants sont utilisés.
FTPS, FTPS implicite, SFTP — Indiquez dans cette boîte de dialogue le nom du serveur, ainsi que le nom d'utilisateur et le mot de passe permettant de s'y connecter. Vous pouvez sélectionner un sous-dossier sur le serveur. Un sous-dossier est indiqué par défaut.
Remarque: Outre l'authentification par mot de passe, il est possible d'utiliser l'authentification par clé privée. Voir la section ci-dessus pour plus d'informations
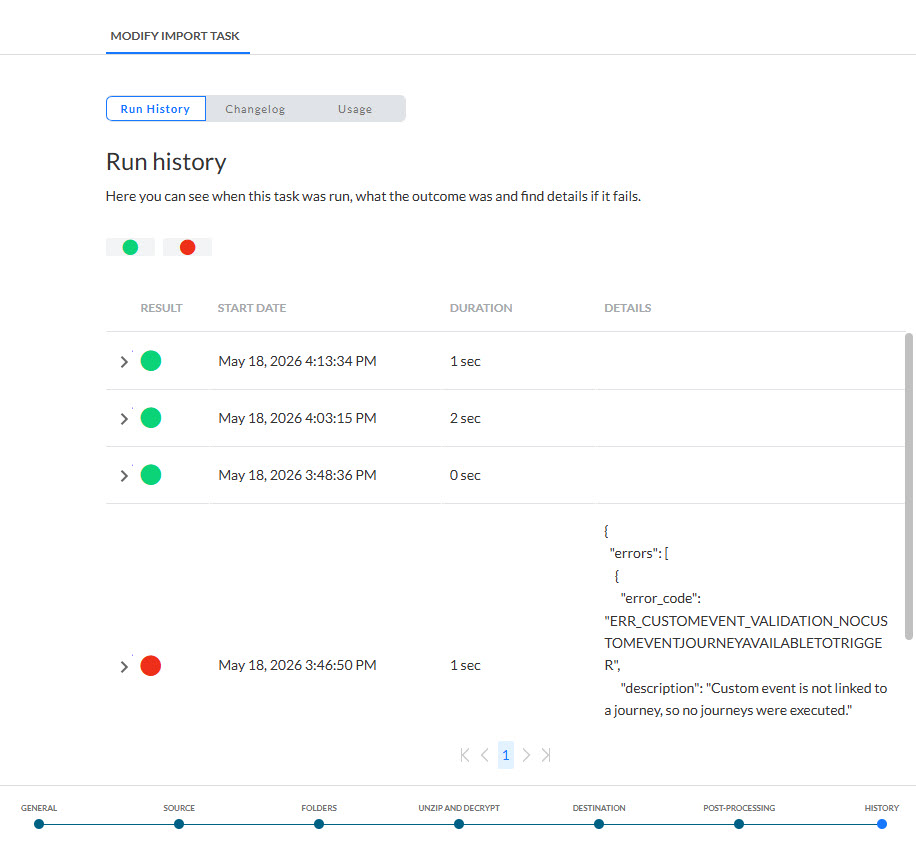
Historique
L'Historique fournit à l'utilisateur des informations sur
- les modifications apportées à cette tâche (mise à jour, suppression) et sur la personne qui les a effectuées. Ces informations sont disponibles dans l'onglet Journal de modifications.
- les différentes exécutions de la tâche et le statut de ces exécutions. Ces informations sont disponibles dans l'onglet Historique de l'exécution. Si la tâche contient des sous-tâches, leur historique de l'exécution peut également être consulté.
- où la tâche est utilisée. Ces informations sont disponibles dans l'onglet Utilisation.
Utilisez les icônes de filtre en haut pour filtrer l'historique de l'exécution.