
JSON-Daten können in einer Importaufgabe verwendet werden, die im Kapitel Datenaustausch von Selligent by Zeta definiert ist.
Es sollte beachtet werden, dass Werte, die in einer JSON-Struktur enthalten sind, nicht nativ in Datenbanktabellen importiert werden können. Die Verarbeitung im Hintergrund wandelt die JSON-Struktur in einen oder mehrere CSV-Streams um, die dann Spalten in einigen temporären Tabellen auffüllen.
Von dort aus ist eine Stored Procedure erforderlich, um Geschäftsdaten aus diesen Zeilen aktualisiert einzufügen, was den Teil „Datenverarbeitung“ der „Nachbearbeitung“ darstellt. Wenn keine Nachbearbeitung erfolgt, verbleiben die Daten in diesen temporären Tabellen im Backend.
Hinweis: Diese temporären Tabellen sind nur über den Datenexplorer von Selligent (oder das SQL-Fenster von Campaign) sichtbar. Die Daten können von Personen, die keinen Zugang zu diesen Funktionen haben, nicht eingesehen werden.
1. Import eines einzelnen Datensatzes
Als Beispiel beginnen wir mit einer einfachen JSON-Datei, die nur eine Datenzeile enthält und wie folgt aussieht:
{
"fullname" : "Penny Haythere",
"email" : "penny@jmail.nl",
"lang" : "Dutch",
"mobile_number" : "0031 234 567890",
"badge" : "013159"
}Hinweis: Sie können diese JSON-Datei hier herunterladen.
Ein XML-Beispiel, das die JSON-Struktur für diesen Datensatz beschreibt, könnte wie folgt aussehen:
<LOADFORMAT>
<TABLE PATH="" NAME="Records" ROOTTABLE="1">
<COLUMN PATH="fullname" />
<COLUMN PATH="email" />
<COLUMN PATH="lang" />
<COLUMN PATH="mobile_number" NAME="mobile" />
</TABLE>
</LOADFORMAT>Erstellen Sie zunächst eine neue Importaufgabe und geben Sie den Pfad als öffentliche URL an (dies erspart das Ablegen der JSON-Datei auf einer FTP-Quelle):
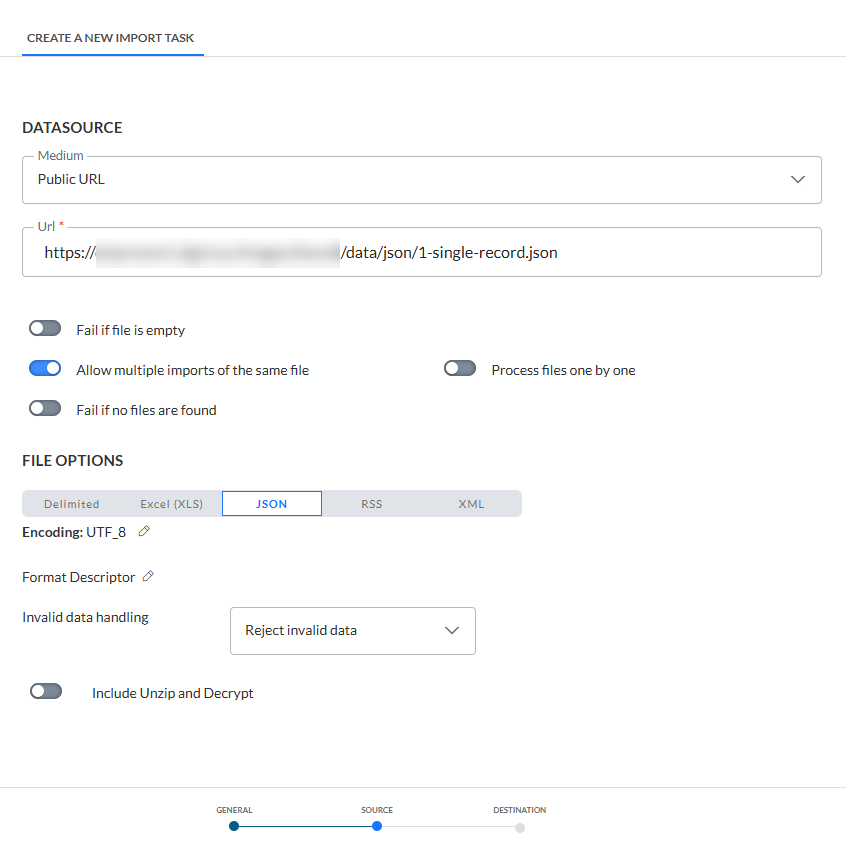
Für den Format-Deskriptor müssen wir das XML-Dokument angeben, das dieses JSON beschreibt:

Einige Angaben zum XML-Dokument:
- Jeder JSON-Schlüssel (Vollname, E-Mail usw.) wird als SPALTE im XML-Dokument angegeben.
- Ein Schlüssel, der im XML-Dokument nicht enthalten ist, wird beim Import nicht berücksichtigt – in diesem Fall wird der JSON-Wert für „badge“ also ignoriert.
- Es wird eine temporäre Tabelle mit den Spalten FULLNAME, EMAIL und LANG erstellt.
- Die letzte Spalte wird MOBILE heißen, da das Attribut „NAME“ den Namen der Spalte angibt. Wenn NAME weggelassen wird, entsprechen die Spalten standardmäßig den PATH-Angaben (in diesem Fall FULLNAME, EMAIL und LANG).
- NAME="Records" gibt an, dass der Name der temporären Tabelle das Format JOB_1234_Records haben wird.
- Die Job-Nummer ist die ID des Campaign-Jobs für die Importaufgabe.
Hinweis: Diese Job-ID ist in Selligent nicht sichtbar, kann aber in den E-Mail-Benachrichtigungen eingesehen werden.
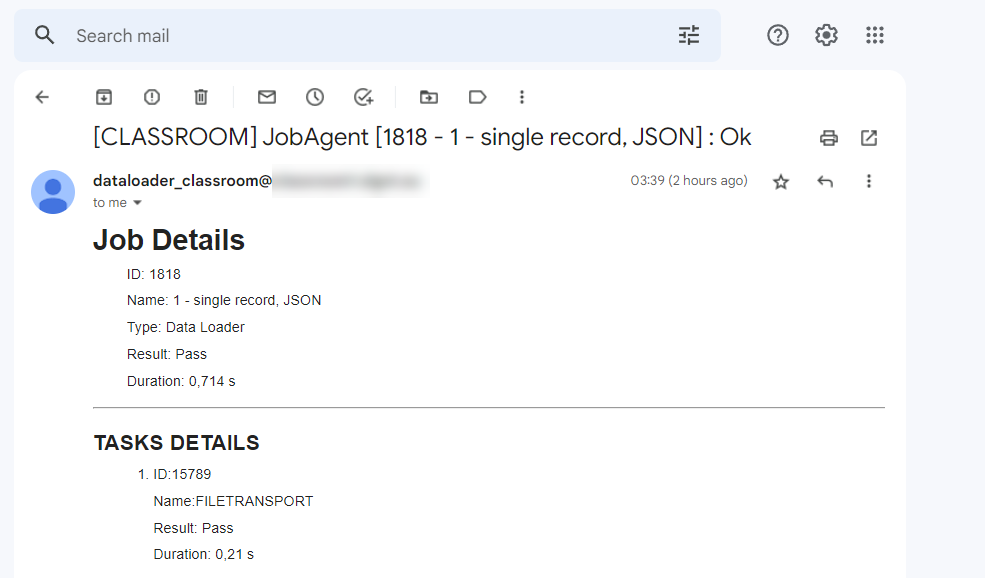
Im obigen Beispiel ist die Job-ID 1818, der Typ Data Loader bezieht sich auf die Importaufgabe, und Name ist der Name der Importaufgabe. - Das Suffix Records wurde in der <TABLE>-Definition angegeben.
- In den JSON-Daten kann es viele hierarchische Ebenen geben, jede mit ihrer eigenen <TABLE>-Deklaration, aber alles wird in einer obersten Ebene enthalten sein, die durch ROOTTABLE=1 und einen leeren PATH-Wert gekennzeichnet ist.
- Das Root-Element des XML-Dokuments ist immer <LOADFORMAT>, so dass alle <TABLE>- und <COLUMN>-Definitionen in diesen Elementen enthalten sein sollten.
- Ein XML-Prolog ist nicht erforderlich.
Auf dem nächsten Bildschirm wird ein Tabellenname gefordert:

Dabei handelt es sich nicht um den Namen der temporären Tabellen, in denen die Daten gespeichert werden, sondern um eine Zwischentabelle, die Informationen über die von den CSV-Streams erstellten temporären Tabellen enthält. Dies wird später noch deutlicher werden, aber für den Moment werden wir den Namen „first“ erwähnen.
Hinweis: Beim Speichern der Aufgabe wird der angegebene Name mit einem bereits vorhandenen Namen verglichen. Im Falle eines Konflikts gibt Selligent einen Fehler aus und weigert sich, die Aufgabe zu speichern.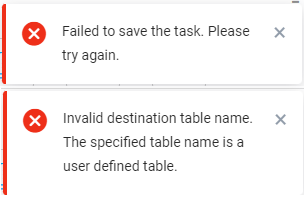
Wenn der Job ausgeführt wurde, sollte der Verlauf bestätigen, dass er wie vorgesehen funktioniert hat:
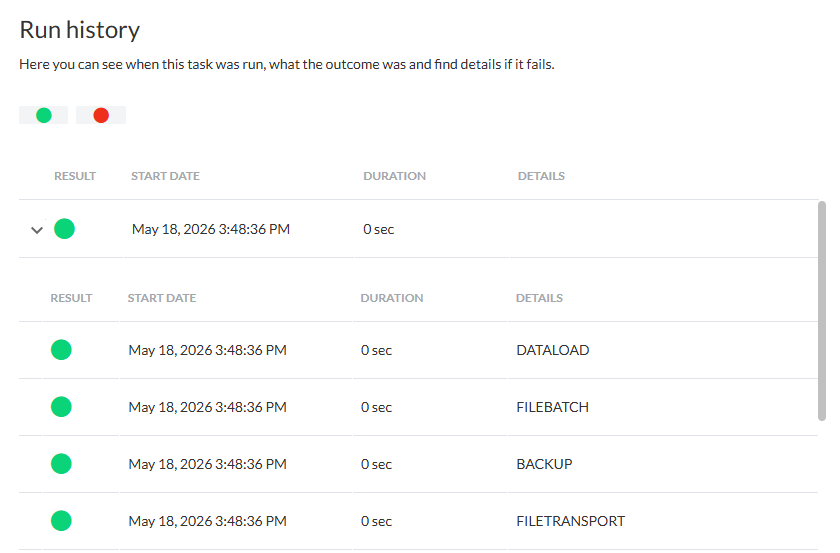
Von hier aus kann der Datenexplorer genutzt werden, um zu sehen, was mit den Daten passiert ist. Die Suche nach dem als Zieltabelle angegebenen Namen zeigt, dass eine neue Tabelle mit diesem Namen existiert:
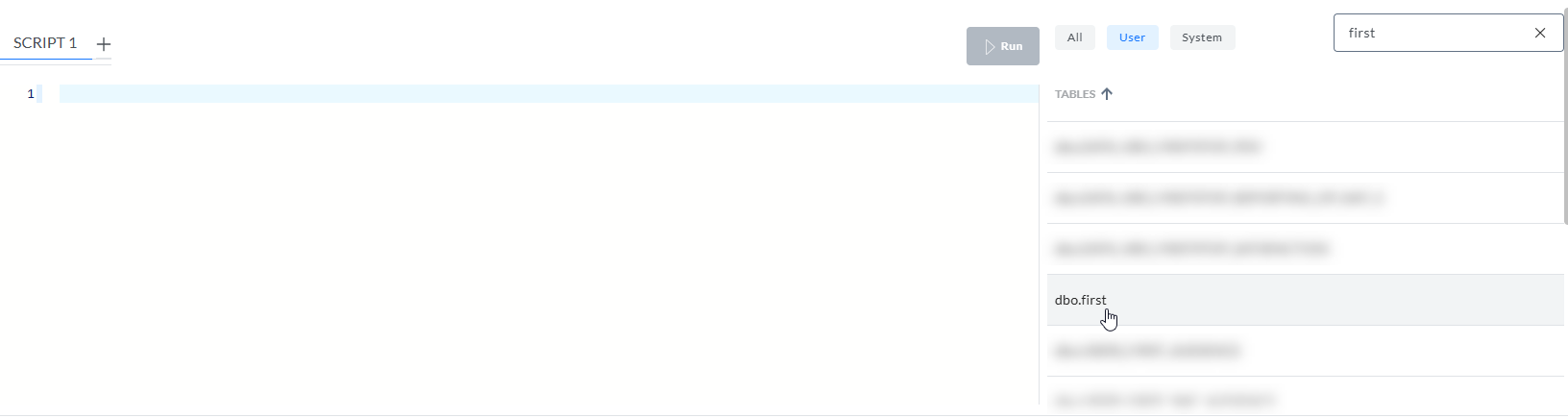
Die Abfrage dieser Tabelle ergibt nur eine Zeile mit dem Tabellennamen JOB_[ID]_Records (d. h. eine CSV-Datei):
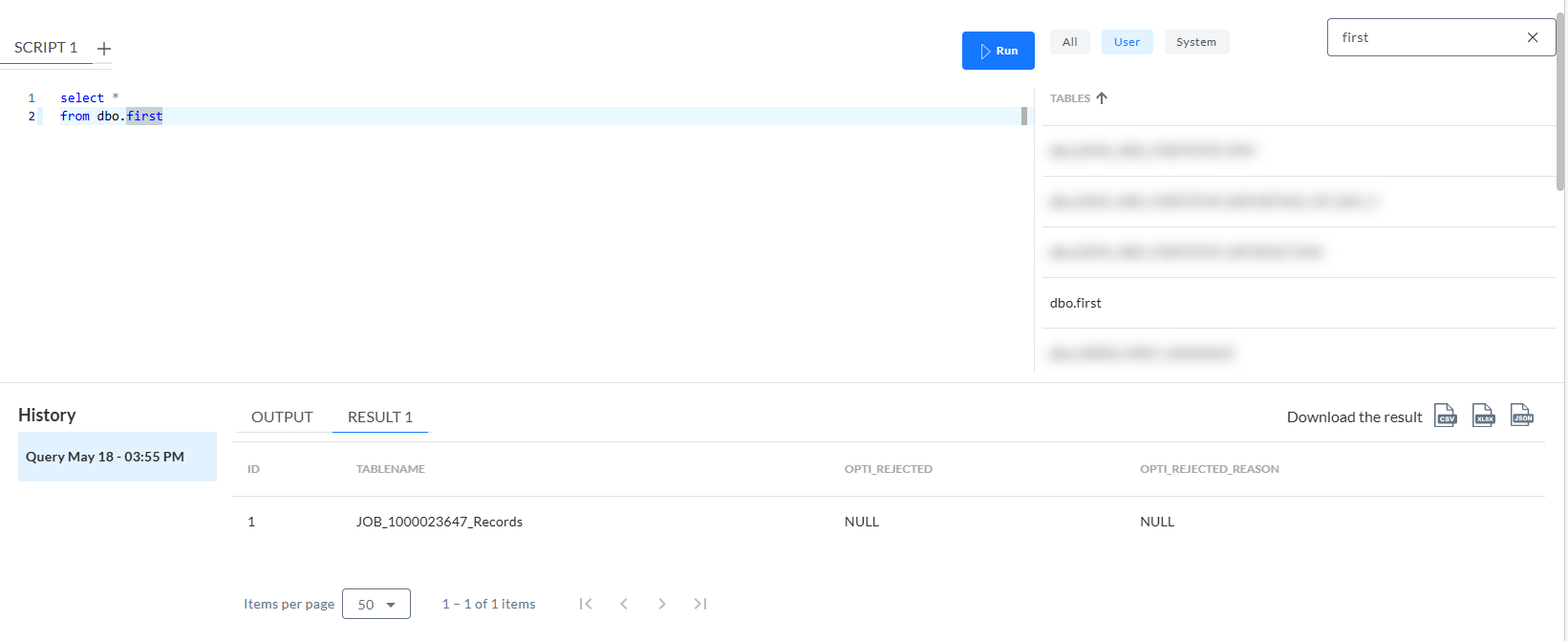
Die Abfrage der Tabelle JOB_[ID]_Records zeigt die Daten selbst an:
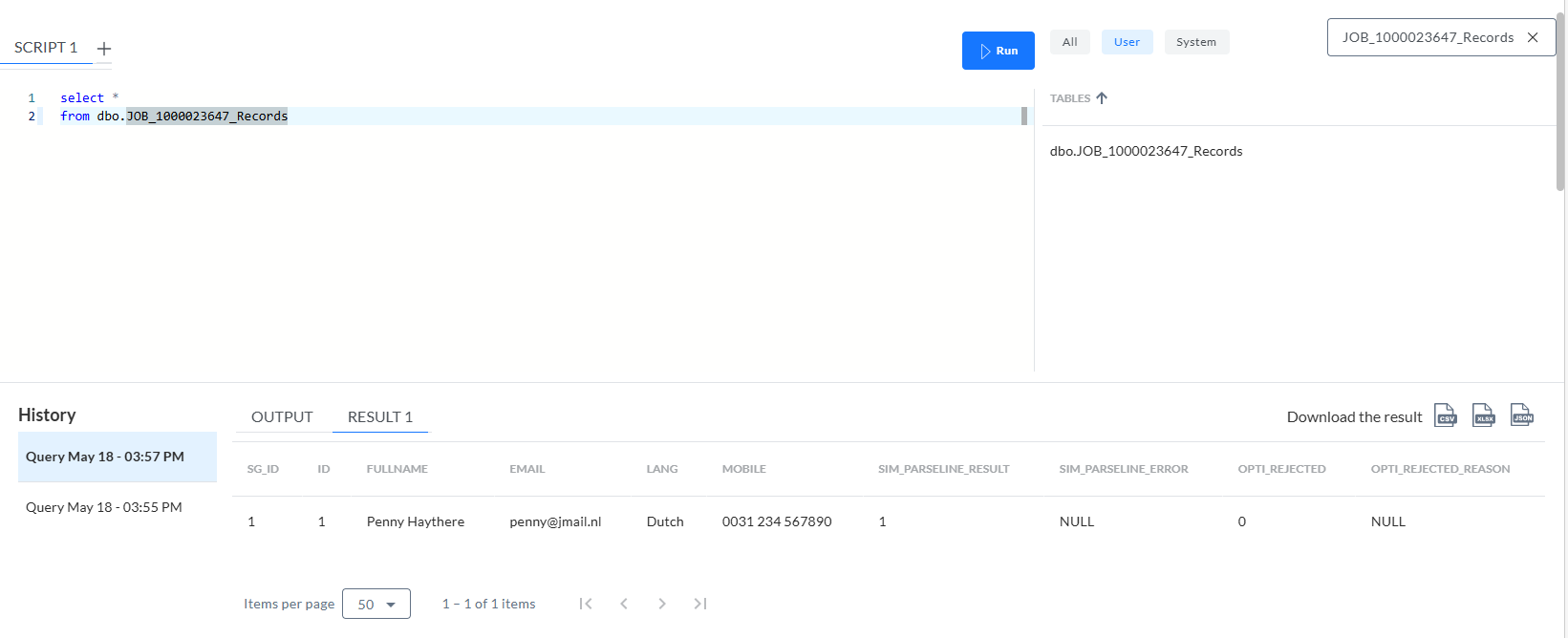
Wie erwartet:
- Der Tabellenname enthält das Suffix _RECORDS aus dem Format-Deskriptor.
- Mit dem Attribut NAME wurde die Spalte MOBILE erstellt.
- Die Spalten FULLNAME, EMAIL und LANG sind standardmäßig mit den Einträgen im PATH vorbelegt, ein NAME fehlt.
2. Import mehrerer Datensätze
Um das vorherige Beispiel zu erweitern, enthält die JSON-Datei dieses Mal mehrere Datensätze in einem Array:
[
{
"fullname" : "Dwayne Rodriguez",
"email" : "rodriguez@laredo.mx",
"lang" : "Spanish",
"mobile_number" : "0052 345 667788"
},
{
"fullname" : "Gottlieb Kiesel",
"email" : "dr.kiesel@hesse.edu.de",
"lang" : "German",
"mobile_number" : "0049 123 445566"
},
{
"fullname" : "Fulbert le Fou",
"email" : "inventor@barn.fr",
"lang" : "French",
"mobile_number" : "0033 456 789789"
}
]Hinweis: Sie können diese JSON-Datei hier herunterladen.
Der Format-Deskriptor, der zur Beschreibung der vorherigen JSON-Datenstruktur verwendet wurde, ist auch hier ausreichend. Wir werden jedoch ein paar Änderungen vornehmen:
<LOADFORMAT>
<TABLE PATH="" NAME="multiple" ROOTTABLE="1">
<COLUMN PATH="fullname" />
<COLUMN PATH="email" NAME="mail"/>
<COLUMN PATH="lang" />
<COLUMN PATH="mobile_number" NAME="mobile" />
</TABLE>
</LOADFORMAT>In diesem Fall gilt:
- Die Spalten FULLNAME, MAIL, LANG und MOBILE werden gefüllt.
- Sie befinden sich in einer Tabelle mit einem Namen wie JOB_1820_MULTIPLE.
- Der Name dieser Tabelle wird eine einzelne Zeile sein, die in der Zwischentabelle erwähnt wird (zuvor „first“).
3. Mehrere Datensätze mit einzelnen Unterschlüsseln
In diesem Fall kann jeder Datensatz statt einer flachen Struktur zusätzliche Informationen als Unterschlüssel (eine Ebene tiefer) enthalten, die möglicherweise mit 1:1 verwandten Daten übereinstimmen:
[
{
"fullname" : "Dwayne Rodriguez",
"email" : "rodriguez@laredo.mx",
"lang" : "Spanish",
"mobile_number" : "0052 345 667788",
"workdetails" :
{
"office" : "Tijuana",
"payrollNo" : 11223344
}
},
{
"fullname" : "Gottlieb Kiesel",
"email" : "dr.kiesel@hesse.edu.de",
"lang" : "German",
"mobile_number" : "0049 123 445566",
"workdetails" :
{
"office" : "Berlin",
"payrollNo" : 55667788
}
},
{
"fullname" : "Fulbert le Fou",
"email" : "inventor@barn.fr",
"lang" : "French",
"mobile_number" : "0033 456 789789",
"workdetails" :
{
"office" : "Paris",
"payrollNo" : 99001122
}
}
]Hinweis: Sie können diese JSON-Datei hier herunterladen.
Ein Beispiel für einen Format-Deskriptor könnte wie folgt aussehen:
<LOADFORMAT>
<TABLE PATH="" NAME="csvfile1" ROOTTABLE="1">
<COLUMN PATH="fullname" />
<COLUMN PATH="email" />
<COLUMN PATH="lang" />
<COLUMN PATH="mobile_number" NAME="mobile" />
<COLUMN PATH="workdetails.office" NAME="workdetails_office"/>
<COLUMN PATH="workdetails.payrollNo" NAME="workdetails_payrollNo"/>
</TABLE>
</LOADFORMAT>
Wir werden eine Zwischentabelle mit dem Namen „multiple“ angeben:
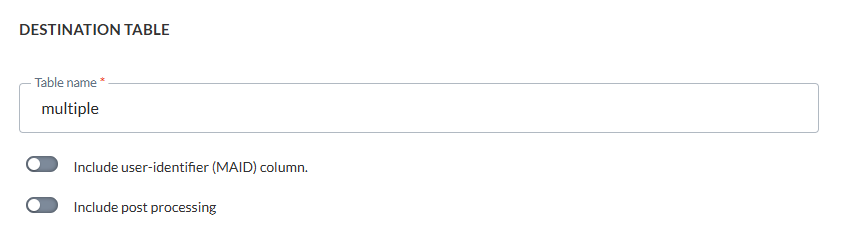
Wenn der Job ausgeführt wurde, finden wir eine Tabelle mit dem Namen „multiple“, die eine Zeile enthält: JOB_[ID]_csvfile1.
Wenn wir diese Tabelle JOB_[ID]_csvfile1 abfragen, sehen wir:
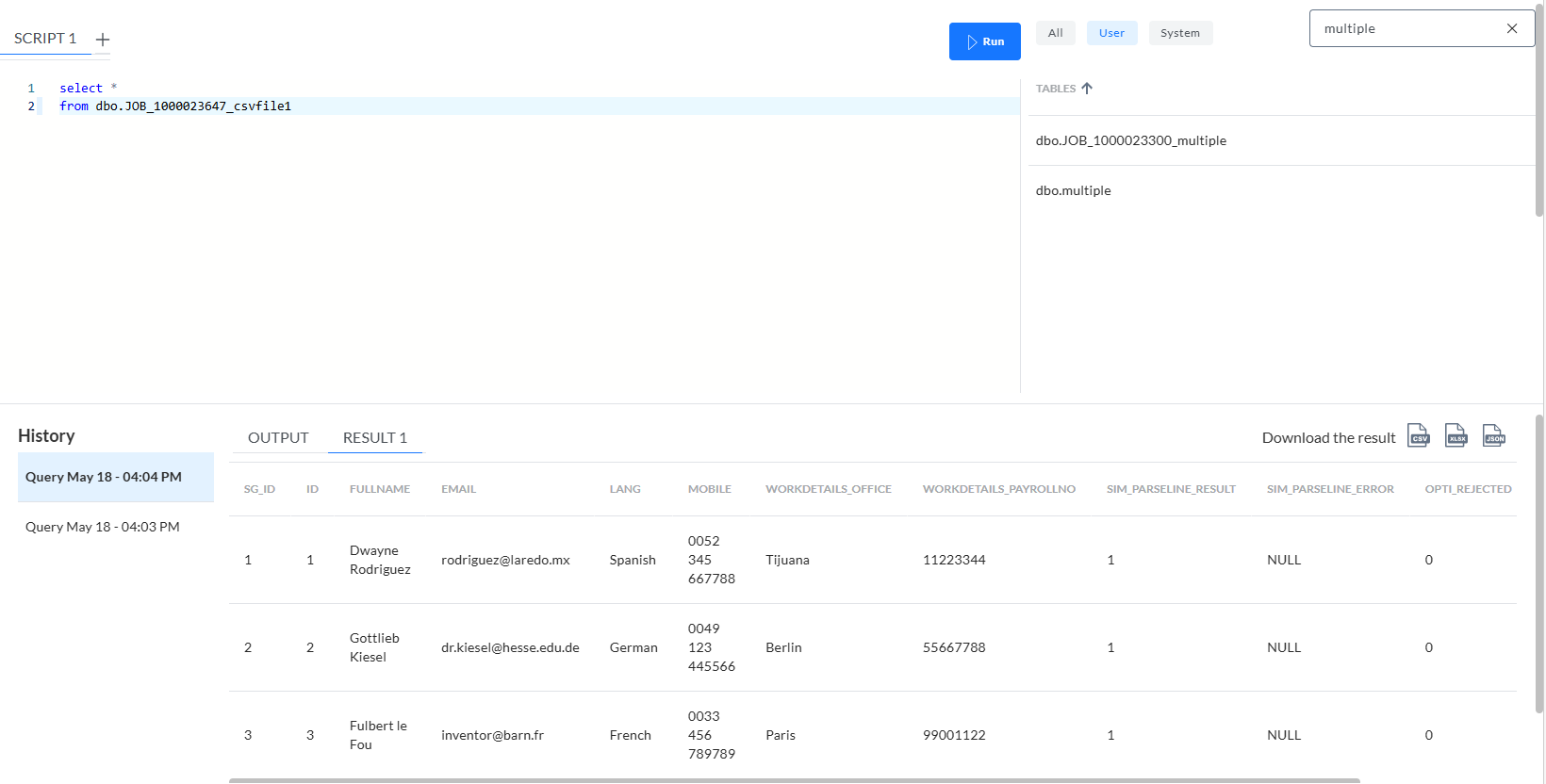
Hinweis:
- PATH="workdetails.office" verwendet einen Punkt als Ebenentrennzeichen
- NAME="workdetails_office" ist der Name der Tabellenspalte, die in dieser Holding-Tabelle erstellt wurde
- Csvfile1 ist der Name, der dieser Tabelle durch den Format-Deskriptor gegeben wird
4. Mehrere Datensätze mit mehreren Unterschlüsseln
Diesmal enthält die JSON-Datei mehrere Datensätze, wobei jeder Datensatz auch ein Array mit mehreren verbundenen Datensätzen enthalten kann, wodurch eine 1:N-Beziehung simuliert wird.
[
{
"fullname" : "Dwayne Rodriguez",
"email" : "rodriguez@laredo.mx",
"lang" : "Spanish",
"mobile_number" : "0052 345 667788",
"subscriptions" : [
{ "magazine" : "GH", "start" : "2016-01-10" }
]
},
{
"fullname" : "Gottlieb Kiesel",
"email" : "dr.kiesel@hesse.edu.de",
"lang" : "German",
"mobile_number" : "0049 123 445566",
"subscriptions" : [
{ "magazine" : "GH", "start" : "2017-05-11" },
{ "magazine" : "SI", "start" : "2018-07-12" }
]
},
{
"fullname" : "Fulbert le Fou",
"email" : "inventor@barn.fr",
"lang" : "French",
"mobile_number" : "0033 456 789789",
"subscriptions" : [
{ "magazine" : "GH", "start" : "2019-09-14" },
{ "magazine" : "SI", "start" : "2020-10-16" },
{ "magazine" : "FM", "start" : "2021-11-18" },
{ "magazine" : "KG", "start" : "2022-12-20" }
]
},
{
"fullname" : "Fiona Starr",
"email" : "hellfire@chopper.edf",
"lang" : "EN",
"mobile_number" : "0044 7890 112233",
"subscriptions" : [ ]
}
]
Hinweis: Sie können diese JSON-Datei hier herunterladen.
Ein Beispiel für einen Format-Deskriptor könnte lauten:
<LOADFORMAT>
<TABLE PATH="" NAME="toplevel" ROOTTABLE="1">
<COLUMN PATH="fullname" />
<COLUMN PATH="email" />
<COLUMN PATH="lang" />
<COLUMN PATH="mobile_number" NAME="mobile" />
<TABLE PATH="subscriptions" NAME="related">
<COLUMN PATH="magazine" NAME="periodical"/>
<COLUMN PATH="start" NAME="START_DT"/>
</TABLE>
</TABLE>
</LOADFORMAT>In diesem Fall
- NAME="toplevel" ist der Name, der der ersten Tabelle durch den Format-Deskriptor gegeben wird.
- <TABLE PATH="subscriptions" kennzeichnet das verschachtelte Array, das als Daten zum Auffüllen einer zweiten Tabelle zu behandeln ist. Der Name wird durch NAME="related" beeinflusst (der endgültige Name enthält das Suffix toplevel_related ).
- Die COLUMN-Definitionen innerhalb dieses <TABLE>-Elements beziehen sich auf die JSON-Schlüssel innerhalb des Arrays und bilden die Felder in der zweiten Tabelle.
Die ausgewählte Zwischentabelle wird als „hierarchical“ bezeichnet:
Die Ergebnisse sind:
-
Dbo.hierarchical enthält zwei Zeilen, die die Tabellennamen anzeigen:
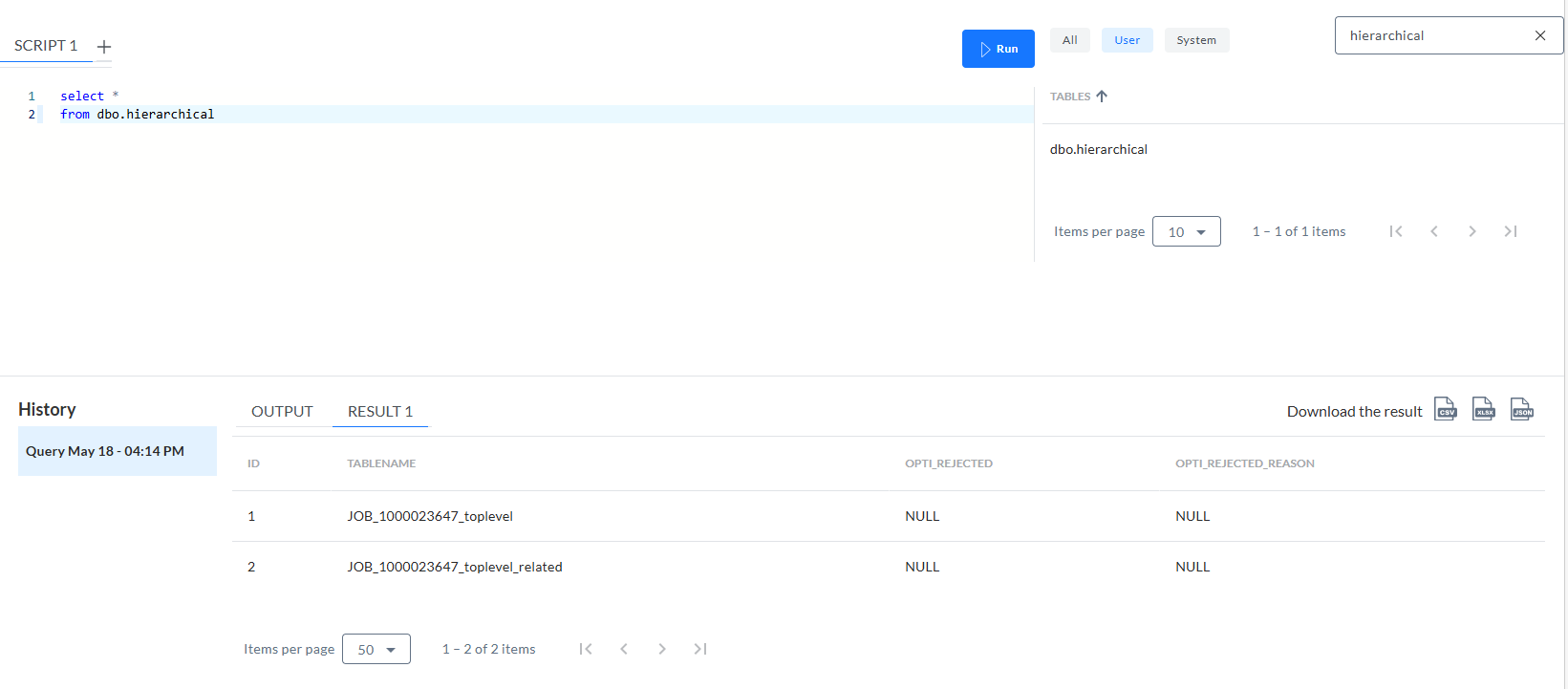
-
JOB_[ID]_toplevel – Tabelle, die 4 Zeilen der Primärschlüssel enthält:
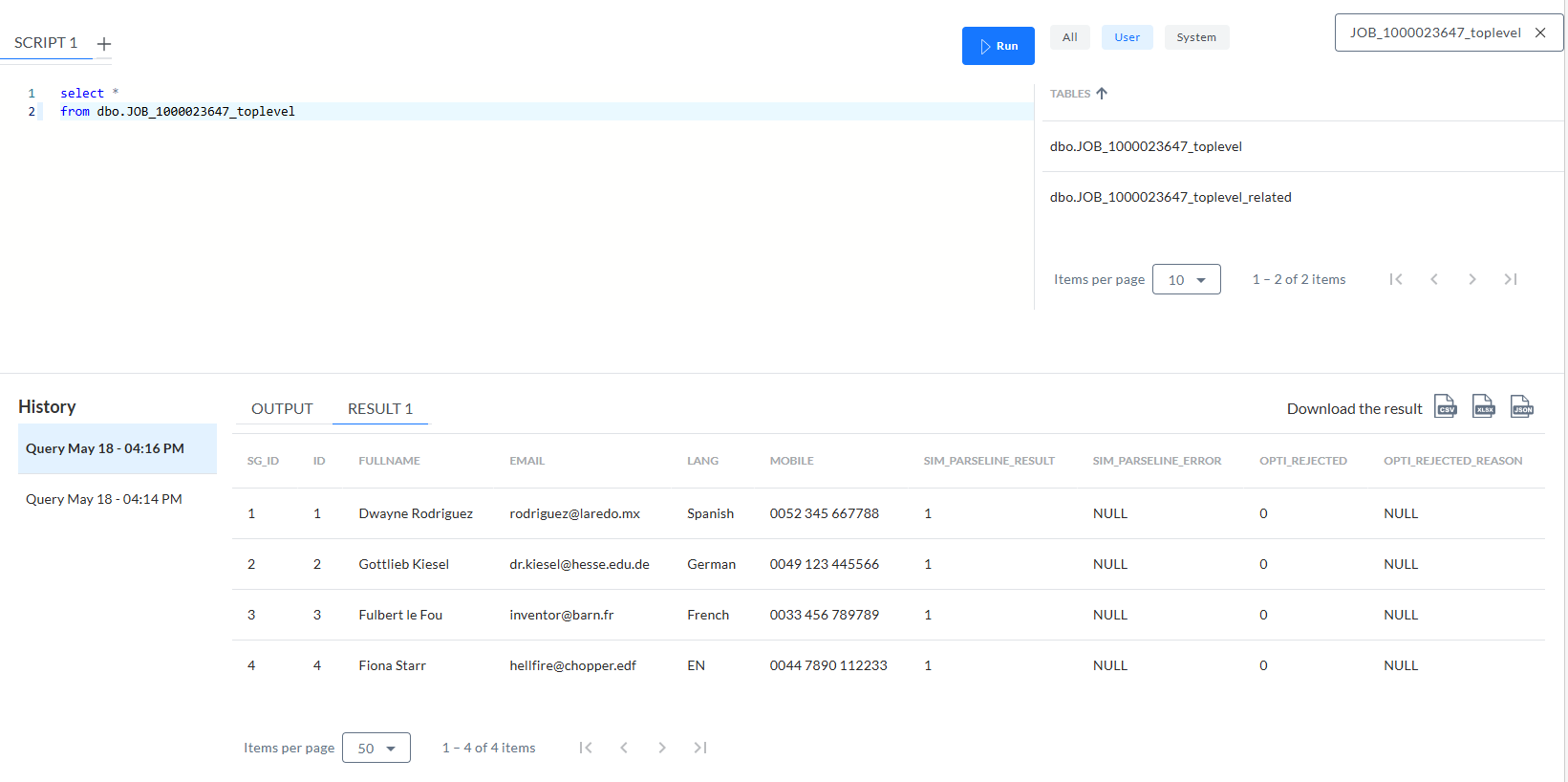
-
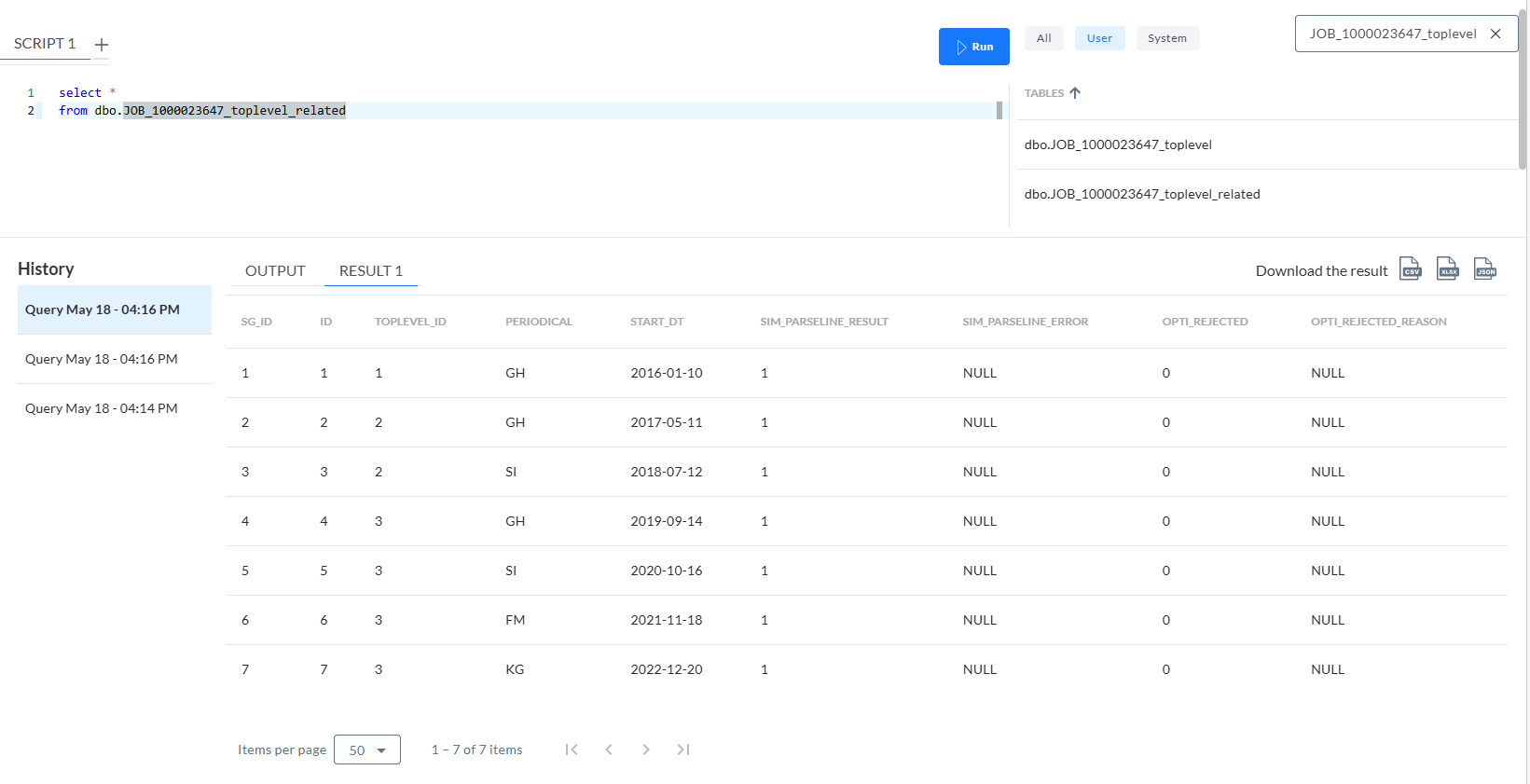
JOB_[ID]_toplevel_related – Tabelle, die 7 Zeilen enthält, wobei TOPLEVEL_ID ein Fremdschlüssel ist, der sich auf die ID der vorherigen Tabelle bezieht:
Campaign
