Eine Importaufgabe kann auf zwei Arten erstellt werden:
- Entweder vom Flyout-Menü aus, das vom Eintrag "Data Exchange" in der linken Navigationsleiste aus verfügbar ist. Klicken Sie auf "+ Neu" und wählen Sie die Art der Aufgabe aus der Dropdown-Liste aus.
- Wählen Sie im Start Seite + Neu > Importaufgabe aus. Ein Assistent führt Sie durch den Erstellungs- und Konfigurationsvorgang.

Hinweis:Die übersicht der Schritte kann verwendet werden, um beim Bearbeiten einer Aufgabe direkt zu einem spezifischen Schritt zu gehen.
- Allgemeine Eigenschaften festlegen
- Quelle definieren
- Optional Nachbearbeitungsordner definieren
- Optional Entzippen und Entschlüsseln
- Ziel definieren
- Verlauf anzeigen
Allgemeine Eigenschaften
In diesem Abschnitt werden Planungs- und Benachrichtigungsoptionen für die Importaufgabe definiert.
Eigenschaften
- Ordnerpfad — Legen Sie den Ordnerpfad für die Aufgabe fest. Dies ist der Ort in der Ordnerstruktur, an dem die Aufgabe gespeichert ist.
- Namen und Beschreibung — Dieser sollte möglichst eindeutig sein, um die Aufgabe im Start Seite leicht erkennen zu können. Make sure to make it as explicit as possible to easily recognize the task in the Start page.
- Komponenten-Label – Das (die) dieser Komponente zugewiesene(n) Label(s). Wählen Sie ein oder mehrere Labels aus der Dropdown-Liste. (Diese Labels werden in der Admin-Konfiguration konfiguriert). Benutzer mit der entsprechenden Zugriffsberechtigung können hier auch neue Labels erstellen, indem sie den neuen Label-Wert in das Feld eingeben.
- API-Namen — Der Name wird verwendet, wenn die Aufgabe über die API ausgeführt wird. Standardmäßig wird der API-Name mit dem Namen ausgefüllt, der der Aufgabe gegeben wurde.
Plan
Der Zeitplanschalter gibt an, ob diese Aufgabe ihre eigene Zeitplanung haben soll. Das ist nicht notwendig, wenn diese Aufgabe Teil einer Batch-Ausführung von Aufgaben (Batch-Job) ist - in diesem Fall erbt sie die Zeitplanung des übergeordneten Batch-Jobs.
Wenn aktiviert, werden im Abschnitt „Zeitplan“ die Gültigkeitsdauer für die Aufgabe sowie das Ausführungsvorkommen definiert.
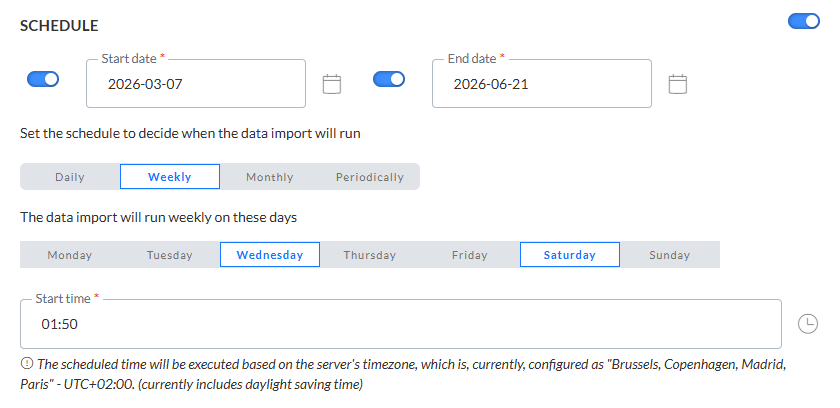
Start- und Enddatum — Sie können ein Startdatum und/oder Enddatum für die Aufgabe einstellen. Zum Beispiel kann Ihre Aufgabe jetzt starten, muss aber unendlich laufen.
Häufigkeit — Geben Sie an, wann die Aufgabe ausgeführt werden soll:
- Täglich — Wählen Sie die Stunden des Tages aus, in denen die Aufgabe ausgeführt werden soll. Sie können mehr als eine ausführen.
- Wöchentlich — Wählen Sie die Tage der Woche aus, an denen die Aufgabe ausgeführt werden soll. Die Aufgabe kann mehr als einmal die Woche ausgeführt werden. Sie können auch die Startzeit festlegen.
- Monatlich — Wählen Sie die Tage des Monats aus, an denen die Aufgabe ausgeführt werden soll. Sie können auch die Tageszeit auswählen, zu der die Aufgabe starten soll.
- Periodisch — Legen Sie das erneute Erfolgen der Aufgabe, in Minuten ausgedrückt, fest. Die Aufgabe wird zum Beispiel alle 10 Minuten ausgeführt.
Hinweis: Die geplante Zeit wird auf Basis der Zeitzone des Servers ausgeführt. Die zurzeit konfigurierte Zeitzone des Servers wird neben dem Info-Symbol angezeigt.
Journey nach Aufgabenausführung auslösen

Diese Option ermöglicht es Ihnen, die Ausführung einer Transaktionale Journey nach erfolgreicher Ausführung einer Aufgabe auszulösen, wenn Sie dies möchten. Dies impliziert, dass die Journey nicht ausgeführt wird, wenn die Aufgabe fehlschlägt, und der Benutzer wird informiert, wenn dies erfolgt.
Wählen Sie eine Ziel-Journey aus der Dropdown-Liste aus. Es können nur Transaktionale Journeys ausgewählt werden.
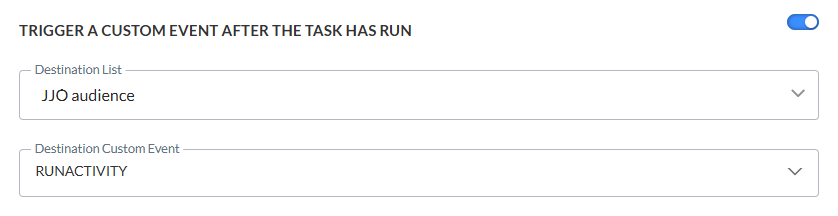
Ereignisgesteuerte Journey nach Aufgabenausführung auslösen
Diese Option ermöglicht Ihnen das Auslösen der Ausführung einer ereignisgesteuerten Journey. Nach dem Importieren von Daten über eine Aufgabe in der benutzerdefinierten Ereignisliste in der Datenbank müssen Sie zum Beispiel die Journey, die diese benutzerdefinierte Ereignisliste verwendet, explizit auslösen, um sicherzustellen, dass die Datensätze verarbeitet werden.
Zuerst müssen Sie die Zielgruppenliste und dann eine verknüpfte benutzerdefinierte Ereignisliste auswählen. Die ausgewählten benutzerdefinierten Ereignislisten können nur in einer Journey gleichzeitig verwendet werden und lösen diese Journey automatisch aus.
Benachrichtigungen
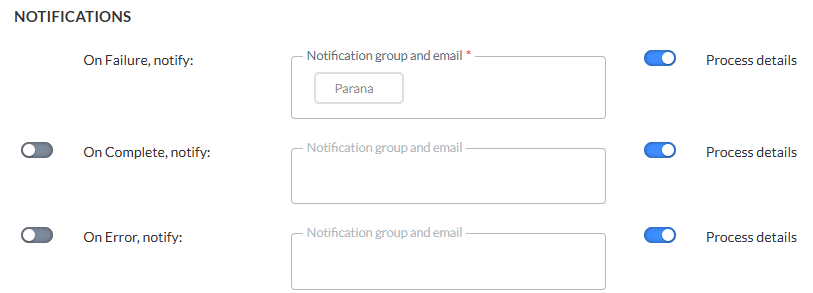
Es kann auch eine Nachricht gesendet werden
- * OnFailure — Bei Fehlschlagen des Prozesses. Dies kann vorkommen, wenn die Daten oder die Spaltenanzahl von Quelle und Ziel nicht übereinstimmen usw. Es ist mindestens eine Benachrichtigungsgruppe / E-Mail-Adresse erforderlich.
- OnComplete — Bei erfolgreichem Abschluss der Aufgabe.
- OnError — Mit Fehlern abgeschlossen (Auftrag wurde abgeschlossen, aber eine oder mehrere Aufgaben führte/n zu Fehlern/Ausnahmen).
- OnNoFile — Wenn keine Datei gefunden werden konnte.
Um die Option zu aktivieren, markieren Sie das Kontrollkästchen und geben Sie eine oder mehrere E-Mail-Adressen ein. (Mehrere E-Mail-Adressen werden durch ein Semikolon getrennt.) Sie können auch eine Benachrichtigungsgruppe auswählen. Diese Benachrichtigungsgruppen werden in der Admin-Konfiguration erstellt.
Hinweis: Benachrichtigungs-E-Mails für das Fehlschlagen der Aufgabe sind obligatorisch. Andere Benachrichtigungen sind optional.
Terminplaner einstellen (Optional)
Hinweis: Der Terminplaner-Abschnitt ist nur sichtbar, wenn Terminplaner für Ihre Umgebung konfiguriert sind. Standardmäßig gibt es 1 Terminplaner. In diesem Fall wird dieser Abschnitt nicht angezeigt, da dieser Standard-Terminplaner verwendet wird. Wenn mehr als 1 Terminplaner konfiguriert ist, haben Sie Zugriff auf den Terminplaner-Abschnitt.
Wenn mehrere Aufgaben, Importe oder Exporte laufen, kann es eine gute Idee sein, einen unterschiedlichen Terminplaner zu verwenden, um sicherzustellen, dass lang laufende Aufgaben kleinere Aufgaben nicht stören. Das Auswählen eines Terminplaners ist optional, und wenn Sie den voreingestellten behalten, werden alle Aufgaben/Exporte/Importe trotzdem ausgeführt, aber wenn es eine größere Aufgabe gibt, wird die kleinere nur ausgeführt, wenn die größere beendet ist.

Sie können zwischen 3 verschiedenen Terminplanern auswählen: dem voreingestellten, dem benutzerdefinierten Terminplaner 1 und dem benutzerdefinierten Terminplaner 2. Wenn Sie verschiedene Terminplaner für Ihre Aufgaben auswählen, werden sie parallel ausgeführt, ohne einander zu stören. Wenn Sie also länger laufende Aufgaben haben, kann es eine gute Idee sein, diese mit einem anderen Terminplaner auszuführen.
Klicken Sie, wenn Sie fertig sind, auf Weiter.
Quelle definieren
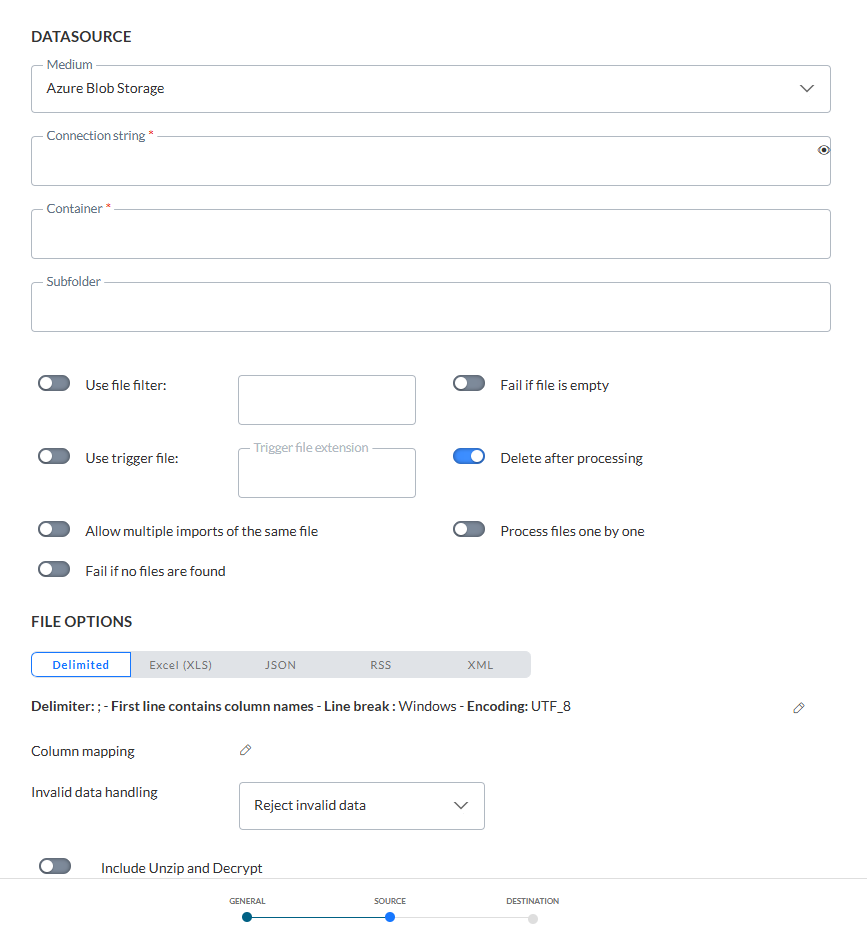
Datenquelle
Der Benutzer kann aus einer Reihe unterschiedlicher Datenquellen auswählen: Repository, Authorized URL, Public URL, Azure Blob Storage, Amazon S3 Storage, Google Cloud Storage, FTPS, SFTP, FTPS implizit. Je nach ausgewähltem Medium sind verschiedene Verbindungsoptionen konfiguriert:
Repository — Der Server, auf dem der Prozess ausgeführt wird, enthält ein lokales Dateisystem mit dem Ordner Campaign-Daten. Sie können einen Unterordner aus der Dropdown-Liste auswählen, aus dem die Importdatei abgerufen wird.
Hinweis: Das Repository ist nur für lokale Kunden verfügbar, da ein Netzwerk- und Serverstandort konfiguriert werden muss.
Öffentliche URL — Geben Sie die URL an. Zugänglich ohne Anmeldung und Passwort und unterstützt HTTP und HTTPS.
Autorisierte URL — Geben Sie die URL und den Benutzernamen und das Passwort für das Verbinden an. Unterstützt nur HTTPS.
Azure Blob-Speicher — Geben Sie die Verbindungszeichenfolge (Sie können die Sichtbarkeit der Zeichenfolge durch Klicken auf das Augensymbol ein- und ausschalten) und den Container und einen optionalen Unterordner an. (*)
Amazon S3-Speicher — Geben Sie die ID des Zugriffsschlüssels und den geheimen Zugriffsschlüssel (Sie können die Sichtbarkeit beider Zeichenfolgen durch Klicken auf das Augensymbol ein- und ausschalten), den Bucket-Namen, den Code des Regionsendpunkts und einen optionalen Unterordner an. (*)
Google Cloud-Speicher — Geben Sie den Typ, die Projekt-ID, die ID des privaten Schlüssels und den privaten Schlüssel (Sie können die Sichtbarkeit beider Zeichenfolgen durch Klicken auf das Augensymbol ein- und ausschalten), die Client-E-Mail, die Client-ID, die Auth-URI, die Token-URI, die URL des Authprovider X509-Zertifikats, die URL des Client X509-Zertifikats, den Bucket-Namen und einen optionalen Unterordner an. (*)
* Hinweis: Details dazu, wie Cloud-Speicherkonfigurationen eingerichtet werden, sind hier zu finden.
Vordefiniert — Beim Auswählen dieser Option wird das Feld „Vordefiniertes Transportmedium“ angezeigt, in dem Sie ein Medium aus einer Liste vordefinierter Medien auswählen können. Diese Medien sind bereits in der Admin-Konfiguration konfiguriert und mit Ihrem Geschäftsbereich verknüpft. Wenn Sie eines auswählen, werden alle entsprechenden Einstellungen verwendet. Sie können einen Unterordner aus der Dropdown-Liste auswählen.
FTPS, FTPS implizit, SFTP — Geben Sie den Namen des Servers und den Benutzer und das Passwort für das Verbinden mit dem Server an. Es kann ein Unterordner auf dem Server ausgewählt werden. Standardmässig ist bereits ein Unterordner ausgewählt. FTPS ist aufgrund der zusätzlichen Sicherheitsschicht im Protokoll die bevorzugte Option.
SFTP kann von Zeta oder einer externen Plattform bereitgestellt werden.
Nur IPs, die sich mit dem Standard-Port 22 verbinden, müssen in die Whitelist aufgenommen werden.
Authentifizierung mit privatem Schlüssel
Bei SFTP kann neben der Verwendung eines Passworts zur Authentifizierung bei der Verbindung mit dem Server auch ein privater Schlüssel verwendet werden:
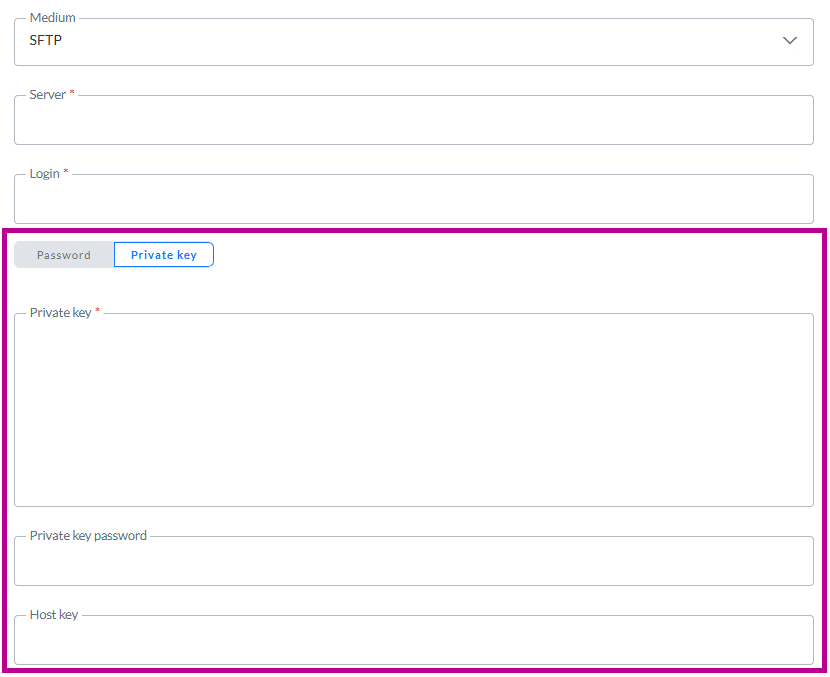
Mit einem Umschalter können Sie entweder Passwort oder Privater Schlüssel auswählen. Wenn Privater Schlüssel ausgewählt ist, können Sie die Daten des privaten Schlüssels in das Feld Privater Schlüssel eingeben (oder mit Copy und Paste einfügen).
Wenn für den privaten Schlüssel ein Passwort erforderlich ist (bei einigen Servern ist dies der Fall), können Sie das Passwort in das Feld Passwort für den privaten Schlüssel eingeben. Dies ist ein optionales Feld.
HinweisDie Daten aus beiden Feldern (privater Schlüssel und Passwort für den privaten Schlüssel) werden verschlüsselt in der Datenbank gespeichert und nur bei der Übertragung der Dateien verwendet
Der Host-Schlüssel ist ein optionales Feld, das als zusätzlicher Überprüfungsschritt verwendet werden kann, um sicherzustellen, dass Sie sich mit dem richtigen Server verbinden.
HinweisBeim Speichern der/des [Importaufgabe/Datenimports/Exportaufgabe/Datenexports/Mediums]:
– Der Inhalt des Feldes für den privaten Schlüssel wird geleert (aus Sicherheitsgründen)
– Das Label des Feldes für den privaten Schlüssel wird auf Einen neuen privaten Schlüssel angeben, um den vorhandenen privaten Schlüssel zu aktualisieren aktualisiert
– Der Inhalt des Feldes für das Passwort des privaten Schlüssels wird geleert (aus Sicherheitsgründen)
– Das Label des Feldes für das Passwort des privaten Schlüssels wird auf Ein neues Passwort für den privaten Schlüssel angeben, um den vorhandenen privaten Schlüssel zu aktualisieren aktualisiert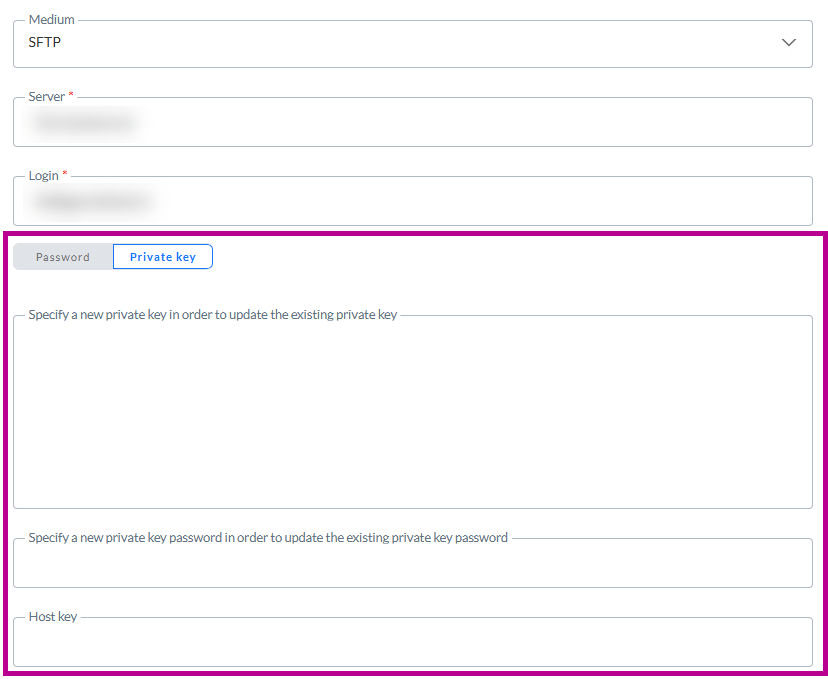
Hinweis: Aufgrund der internen Sicherheit, die innerhalb der SAAS-Umgebung durchgesetzt wird, sind FTP-Übertragungen von und zu externen Servern nur auf Standard-FTP-Ports erlaubt.
Hinweis: Wenn der Benutzer nicht das Recht hat, Medien zu definieren, ist der Medium-Abschnitt beim Bearbeiten der Aufgabe schreibgeschützt und beim Erstellen einer neuen Aufgabe kann nur ein vordefiniertes Medium ausgewählt werden.
Auf den obigen Dateiort folgen mehrere zusätzliche Optionen:
Dateifilter verwenden — Filtern Sie die zu importierenden Dateien. Der Dateimaskenfilter verwendet die angegebenen Werte als Suchmuster. Nur Dateinamen, die dem Muster entsprechen, werden ausgewählt. Sie können zum Beispiel die Erweiterungen der Dateien eingeben, die importiert werden müssen. Sie können * als Platzhalterzeichen verwenden und Sie können einige Personalisierungsfelder verwenden, wie z. B. das aktuelle Datum.
Fehlgeschlagen, wenn Datei leer ist — Legt fest, ob der Import fehlschlägt, wenn die Datei leer ist.
Trigger-Datei verwenden — Eine Trigger-Datei kann verwendet werden. Markieren Sie die Option und geben Sie die Erweiterung der Datei ein. Die Hauptfunktion einer Trigger-Datei besteht darin, zu überprüfen, ob die Hauptdatendatei bereits vollständig hochgeladen worden ist. Es kann vorkommen, dass ein Data-Loader eine Datei aufgreift, während sie noch auf das Medium übertragen wird. Die Trigger-Datei ist jedoch viel kleiner und wird direkt nach Abschluss der Übertragung erstellt, so dass beim Datenladen kein Zweifel besteht, wann die Datei verarbeitet werden kann.
Hinweis: Die Trigger-Datei hat denselben Namen wie die Importdatei, jedoch eine andere Erweiterung.
Nach Bearbeitung löschen — Markieren Sie diese Option, wenn die Datei nach dem Laden gelöscht werden kann.Diese Option wird normalerweise bei Verwendung dynamischer Dateinamen verwendet. Wenn Sie dynamische Dateinamen verwenden, sollten Sie diese Option aktivieren. Ist dies nicht der Fall, schlägt das Datenladen entweder fehl (wenn die Option „Mehrere Importe desselben Dateinamens zulassen“ aktiviert ist) oder jede Datei wird in jedem Intervall aufgegriffen und verarbeitet. Letzteres ist nie eine gute Idee. Wenn Sie die Option „Datei nach Verarbeitung löschen“ nicht aktivieren und die Datei nicht vor jedem Ausführungsintervall überschrieben wird, werden letztendlich alle Datensätze mit den „alten“ Daten aus einer früheren Importdatei überschrieben.
Mehrere Importe derselben Datei erlauben — Eine Importdatei kann mehr als einmal hochgeladen werden und die Liste der hochgeladenen Dateien wird im Zeitverlauf gepflegt. Wenn die Option nicht markiert ist, ist daher ein Import mit demselben Dateinamen am selben Tag nicht erlaubt.
Hinweis: Um jedoch die mehreren Datenlasten zu verfolgen und zu protokollieren, sollte diese Option immer aktiviert sein. Mit einem eindeutigen Dateinamen können mehr Informationen erhalten werden.
Fehlgeschlagen, wenn keine Datei gefunden wird — Legt fest, ob das Laden fehlschlägt, wenn keine Dateien gefunden werden, die mit dem Dateifilter übereinstimmen.Verwenden Sie diese Option, wenn der Import eine Datei für die Verarbeitung im definierten Intervall erfordert.
Dateien nacheinander verarbeiten — Wenn dies markiert ist, werden alle Dateien über den gesamten Prozess vom Herunterladen über die Verarbeitung und die endgültige Behandlung der Datei auf dem Server nacheinander verarbeitet. Wenn es ein Problem mit einer der Dateien gibt, werden die anderen Dateien trotzdem verarbeitet. Wenn die Option nicht markiert ist, wird die weitere Verarbeitung abgebrochen, wenn ein Problem in einer der Dateien auftritt.
Dateioptionen
Sie können zwischen fünf Dateitypen auswählen:
- Getrennt — Dateien mit Trennzeichen sind Dateien, die Komma, Semikolon, Pipe oder Tabulator als Trennzeichen für Spalten verwenden..
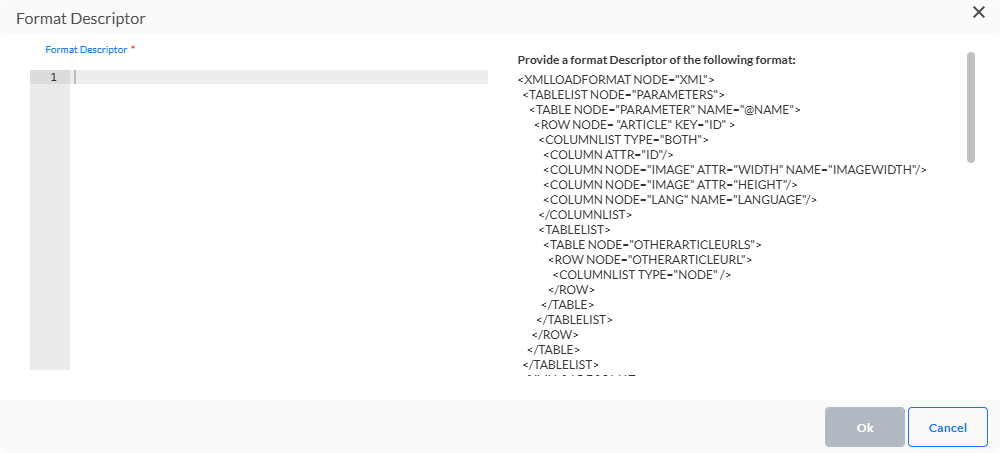
- XML — Die ankommende XML-Datei muss analysiert werden. Der XML-Format-Deskriptor erlaubt das Definieren von Tabellen und Feldern, die aus der XML-Datei abgeleitet werden müssen. (technischer Hinweis zum Analysieren von XML)
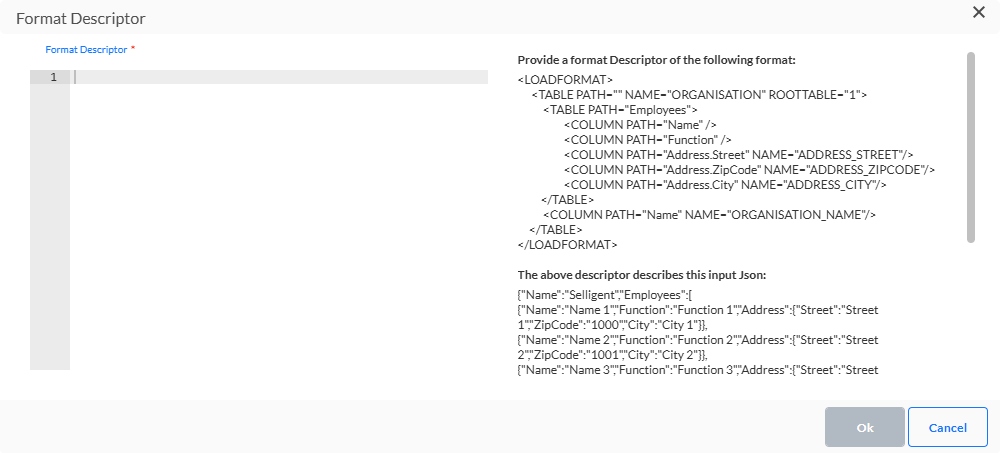
- JSON — Die ankommende JSON muss analysiert werden. Der JSON-Format-Deskriptor erlaubt das Definieren von Tabellen und Feldern, die aus der JSON abgeleitet werden müssen.
- Excel — Eine Excel-Datei mit oder ohne Zeilenüberschriften kann als Importdatei verwendet werden. Hier können XLS und XLSX verwendet werden. Wenn im XLS mehrere Blätter verfügbar sind, wird nur das ausgewählte importiert.
- RSS — Der Rootknoten der RSS-Datei muss angegeben werden.
Getrennt

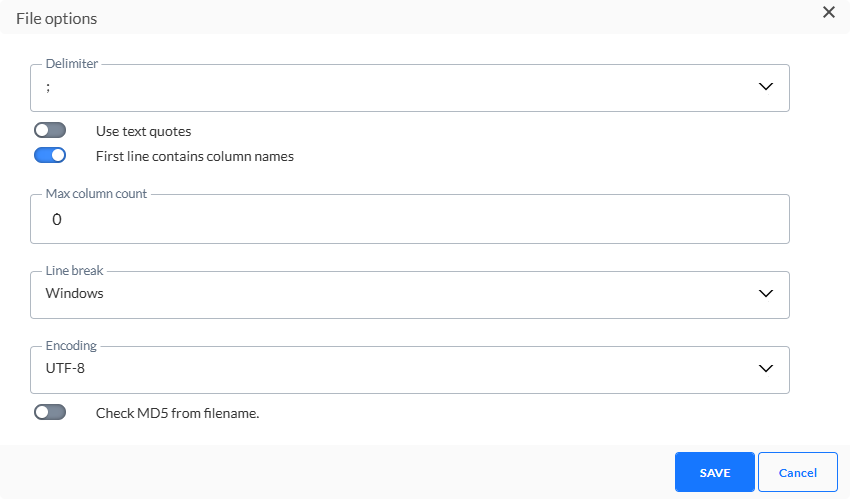
Trennzeichen — Legt das Trennzeichen der Datei fest. Es kann zwischen Tabulator, Doppelpunkt, Semikolon und Pipe-Zeichen ausgewählt werden. Standard ist ;
Text-Anführungszeichen verwenden — Das Einschließen des Texts mit doppelten Anführungszeichen ist möglich. Sollte dies der Fall sein, werden alle alphanumerischen Daten in Anführungszeichen gesetzt und es ist sichergestellt, dass ein Feld, das das Trennzeichen enthält, nicht als zusätzliche Spalte interpretiert wird
Beispiel: In einer durch ein Pipe-Zeichen getrennten Datei würde
;My favorite|color : darauf hinweisen, dass es zwei Felder gibt, aber durch die Anführungszeichen am Anfang und am Ende des Textes wird es als ein Feld betrachtet.„My favorite|color“
Die erste Zeile enthält Spaltennamen — Sie können außerdem die erste Zeile als diejenige festlegen, die die Spaltennamen enthält. Dies Option ist standardmäßig auswählt und wird empfohlen, da die Spaltennamen der Datei in die Spaltenüberschriften Ihrer Tabelle übersetzt werden.
Hinweis: Wenn eine Datei die Kopfzeile mit Spaltennamen, aber keine Daten enthält, handelt es sich nicht um eine leere Datei, sondern um eine gültige Datei ohne Datensätze. Sie wird daher ohne Fehler verarbeitet.
Max. Spaltenzahl — Die maximale Anzahl von Spalten, die in der Datei zulässig sind. Aufgrund des dynamischen Charakters der Datenladeaufgabe, bei der sich die Staging-Tabelle automatisch an den Inhalt der Flat-File anpasst, kann es sinnvoll sein, eine Obergrenze für die Spalten festzulegen, die erstellt werden können.
Zeilenumbruch — Stellen Sie den Zeilenumbruch entweder auf Windows oder Unix ein. Windows verwendet Carriage Return und Line Feed ("\r\n") als Zeilenende, während Unix nur Line Feed ("\n") verwendet.
Codierung —Legen Sie die Art der Codierung fest, die auf die Datei angewandt werden soll. Klicken Sie auf die Dropdown-Liste, um auf eine umfassende Liste von Codiermechanismen zuzugreifen.
MD5 aus Dateiname prüfen — Diese Option wird verwendet, um den Inhalt der Datei nochmals zu prüfen. Dieser MD5-Schlüssel wird zum Dateinamen hinzugefügt und auf Basis des Inhalts der Datei erstellt. Wenn die Option aktiviert ist, wird der MD5-Schlüssel gegenüber dem Inhalt der Datei geprüft. Dies ermöglicht die Erkennung von änderungen in der Datei.
XML

Codierung — Legen Sie die Art der Codierung fest, die auf die Datei angewandt werden soll. Klicken Sie auf das Stiftsymbol, um auf ein Dialogfeld und eine umfassende Liste von Codiermechanismen zuzugreifen. Außerdem wird die Option „MD5 aus Dateiname prüfen“ verwendet, um den Inhalt der Datei erneut zu prüfen. Dieser MD5-Schlüssel wird zum Dateinamen hinzugefügt und auf Basis des Inhalts der Datei erstellt. Wenn diese Option aktiviert ist, wird der MD5-Schlüssel gegenüber dem Inhalt der Datei geprüft und dies ermöglicht die Erkennung von Änderungen in der Datei.
JSON
Codierung — Legen Sie die Art der Codierung fest, die auf die Datei angewandt werden soll. Klicken Sie auf das Stiftsymbol, um auf ein Dialogfeld und eine umfassende Liste von Codiermechanismen zuzugreifen. Außerdem wird „MD5 aus Dateiname prüfen“ verwendet, um den Inhalt der Datei erneut zu prüfen. Dieser MD5-Schlüssel wird zum Dateinamen hinzugefügt und auf Basis des Inhalts der Datei erstellt. Wenn diese Option aktiviert ist, wird der MD5-Schlüssel gegenüber dem Inhalt der Datei geprüft und dies ermöglicht die Erkennung von Änderungen in der Datei.
Excel

Blattname — Der Name des Blatts in der xls-Datei für den Import. Wenn mehrere Arbeitsblätter vorliegen, wird nur das benannte Arbeitsblatt verarbeitet, alle anderen Arbeitsblätter werden ignoriert. Falls mehrere Arbeitsblätter zu verarbeiten sind, müssen sie als einzelne XLSX-Dateien behandelt werden, da jeweils nur ein Arbeitsblatt importiert werden kann.
Die erste Zeile enthält Spaltennamen. — Wählen Sie die Option aus, wenn die oberste Zeile in Ihrem Blatt die Spaltennamen enthält.
Zu überspringende Zeilen — Geben Sie die Nummern der Zeilen in der Datei an, die ausgeschlossen werden sollen.
Codierung — Legen Sie die Art der Codierung fest, die auf die Datei angewandt werden soll. Vom Dropdown aus können Sie auf eine umfassende Liste von Codiermechanismen zugreifen. Außerdem wird „MD5 aus Dateiname prüfen“ verwendet, um den Inhalt der Datei erneut zu prüfen. Dieser MD5-Schlüssel wird zum Dateinamen hinzugefügt und auf Basis des Inhalts der Datei erstellt. Wenn diese Option aktiviert ist, wird der MD5-Schlüssel gegenüber dem Inhalt der Datei geprüft und dies ermöglicht die Erkennung von Änderungen in der Datei.
RSS

Rootknoten (optional) — Der Rootknoten, von dem alle untergeordneten Knoten abgerufen werden. Wenn der Rootknoten nicht konfiguriert ist, ist der voreingestellte Xpath, in dem Daten erwartet werden, der Channel-Knoten. Wenn der Rootknoten konfiguriert ist, können Sie diesen Namen verwenden.
Hinweis: Alle <item>-Elemente und ihr Inhalt innerhalb des Rootknotens (z. B. <channel>) können importiert werden. Wenn andere Elemente direkt unter dem Root-Element erscheinen (auf derselben Ebene wie <item>-Elemente), werden diese nicht importiert.
Beispeil 1 — Wenn wir keinen Rootknoten konfigurieren, wird der Knoten „channel“ aus dieser RSS-Datei standardmäßig als Rootknoten verwendet (das Element und seine Details werden importiert):
<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<item>
<title>News of today</title>
<link>https://www.xul.fr/en-xml-rss.html</link>
<description>RSS item 1</description>
<name>Siyashree</name>
</item>
</channel>
</rss>Beispiel 2 — Wir konfigurieren ein „customrss“-Element als Rootknoten. Es wird als Root in der folgenden RSS-Datei verwendet (das Element und seine Details werden importiert):
<?xml version="1.0" ?>
<rss version="2.0">
<customrss>
<item>
<title>News of today</title>
<link>https://www.xul.fr/en-xml-rss.html</link>
<description>RSS item 1</description>
<name>Siyashree</name>
</item>
</customrss>
</rss>Codierung — Legen Sie die Art der Codierung fest, die auf die Datei angewandt werden soll. Klicken Sie auf die Dropdown-Liste, um auf eine umfassende Liste von Codiermechanismen zuzugreifen.
MD5 aus Dateiname prüfen — Diese Option wird verwendet, um den Inhalt der Datei nochmals zu prüfen. Dieser MD5-Schlüssel wird zum Dateinamen hinzugefügt und auf Basis des Inhalts der Datei erstellt. Wenn die Option aktiviert ist, wird der MD5-Schlüssel gegenüber dem Inhalt der Datei geprüft. Dies ermöglicht die Erkennung von Änderungen in der Datei.
Hinweis: Bei der Verwendung von RSS-Dateien wird standardmäßig Media RSS* unterstützt.
* Was ist Media RSS? Es handelt sich um eine RSS-Erweiterung, die mehrere Verbesserungen für RSS-Anhänge hinzufügt und für die Syndication von Multimedia-Dateien in RSS-Feeds verwendet wird. Ursprünglich wurde es 2004 von Yahoo! und der Media-RSS-Gemeinschaft entwickelt, aber 2009 wurde seine Entwicklung an das RSS Advisory Board übertragen.
Bitte konsultieren Sie https://www.rssboard.org/media-rss für weitere Informationen
Beispiel für eine RSS-Datei mit Medieninhalten :
<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<item>
<title>The latest video from an artist</title>
<link>http://www.foo.com/item1.htm</link>
<media:content url="http://www.foo.com/movie.mov" fileSize="12216320" type="video/quicktime" expression="full">
<media:player url="http://www.foo.com/player?id=1111" height="200" width="400" />
<media:hash algo="md5">dfdec888b72151965a34b4b59031290a</media:hash>
<media:credit role="producer">producer's name</media:credit>
<media:credit role="artist">artist's name</media:credit>
<media:category scheme="http://blah.com/scheme">
music/artistname/album/song
</media:category>
<media:text type="plain">
Some text
</media:text>
<media:rating>nonadult</media:rating>
<dcterms:valid>
start=2002-10-13T09:00+01:00;
end=2002-10-17T17:00+01:00;
scheme=W3C-DTF
</dcterms:valid>
</media:content>
</item>
</channel>
</rss>
Spaltenzuordnung
Spaltenzuordnung ermöglicht Ihnen die Zuordnung der Spalten in der Datenbank zu den Spalten in der Importdatei. Die Spaltenzuordnung definiert die Struktur der erwarteten Datei. Felder können hier manuell mit Namen, Typ und Länge hinzugefügt werden.
Technischer Hinweis: Das Hinzufügen von Spaltenzuordnungen ist für erfolgreiches Datenladen unerlässlich. Wenn also keine Konfiguration zum Festlegen der Spaltendefinition vorgenommen wird, werden Warnungen ausgelöst. Wenn keine Spaltenzuordnung definiert ist, werden alle Spalten der Staging-Tabelle mit Typ NVARCHAR(MAX) erstellt. Dieser Datentyp hat einige erhebliche Nachteile. Daher sollte das Hinzufügen einer Spaltenzuordnung als Voraussetzung betrachtet werden, um sicherzustellen, dass:
- Sie implizite Umwandlungen beim Migrieren der Daten von der Staging- zur Produktionstabelle vermeiden können. - die Datentypen bereits richtig definiert sind und die richtige Spaltenzuordnung aktiviert ist, wobei sie mit dem Datentyp der Produktionsdatenbank übereinstimmen sollten.
-Sie benötigen nur ein Minimum an Speicherplatz, wenn Sie diese Daten in der Staging-Tabelle speichern. Denken Sie daran, dass Sie für jedes Unicode-Zeichen oder n(var)char zwei Bytes benötigen. Dieser Datentyp führt zu massiven Lesevorgängen, die vermieden werden können, wenn geeignetere Datentypen verwendet werden. Letzteres gilt vor allem dann, wenn die Schlüsselwerte, auf denen der UPSERT in Ihrem Datenladen-SP basiert, vom Typ nchar sind.
- Sie können Indizes erstellen. Man kann keine Indizes in Felder setzen, deren Gesamtsumme für Datentyp * Länge die 900-Byte-Marke überschreitet. Daher ist die Platzierung von Indizes auf NVARCHAR(MAX) datenbanktechnisch einfach nicht möglich.
-Auch ohne die Vorteile auf DB-Ebene gibt es eine Menge Leistungsgewinne bei der Implementierung von Spaltenzuordnungen. Am offensichtlichsten ist, dass mehr Datensätze aus der Flat-File in den Speicher geladen und gleichzeitig an die DB übertragen werden können, da die endgültigen Datentypen bekannt sind.
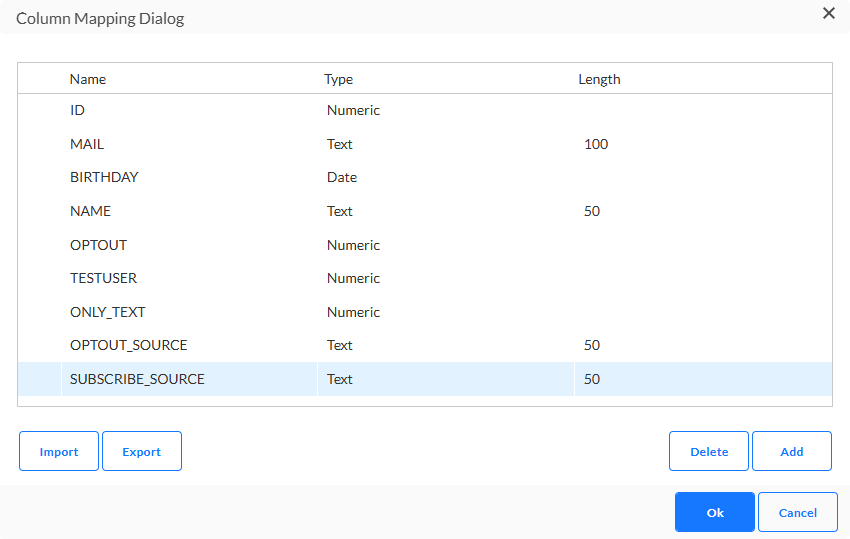
Verwenden Sie die Schaltfläche Exportieren, um die aktuell definierte Zuordnung in eine CSV-Datei zu exportieren. Verwenden Sie die Schaltfläche "Importieren", um eine vorhandene CSV-Datei zu importieren und die Struktur der Datei für die Zuordnung zu verwenden.
Zusätzliche Optionen
Ungültige Datenbehandlung — Dies definiert die Vorgehensweise, wenn ungültige Daten vorhanden sind. Es handelt sich hauptsächlich um Begrenzer- und Datentypfragen. Die folgenden Optionen stehen zur Auswahl:
- Ungültige Daten ablehnen – markiert ungültige Datensätze als abgelehnt und der gesamte Inhalt einer Zeile in der Quelldatei wird zusammen mit einer Beschreibung des Fehlers in einer Ablehnungsdatei abgelegt.
- Ungültige Daten überspringen – fährt fort, ohne auf die ungültigen Daten zu reagieren. Möglicherweise kommen bestimmte Zeilen für den Import nicht in Frage, z. B. wegen falscher Betragsbegrenzer, falscher Datentypen, Trunkierungsfehlern, ... . Wenn Sie diese Option aktivieren, werden diese Datensätze in der Flat-File übersprungen und es wird mit dem nächsten fortgefahren. Wenn Sie diese Option aktivieren, raten wir Ihnen, sie immer in Verbindung mit den folgenden Funktionen zu verwenden.
- Ungültige Daten behalten – speichert die Daten in der Stagingtabelle. Die ursprünglichen Daten werden jedoch in einem einzigen Feld (als Text) gespeichert, anstatt die erforderlichen Felder der Staging-Tabelle zu vervollständigen. Wie diese Daten verarbeitet werden, bleibt Ihnen überlassen.
- Bearbeitung stoppen – stoppt den Prozess komplett und gibt einen Fehler aus.
Verarbeitungsordner verwenden — Wenn diese Option verwendet wird, können Sie mehr kontrollieren und besser prüfen, was während der Bearbeitung der Datei passiert. Diese Option ist nur für die externe Dateiserver-Datenquellen (FTP) verfügbar. Wenn diese Option markiert ist, wird ein zusätzlicher Schritt zum Assistenten hinzugefügt.
Während der Verarbeitung werden Dateien im Verarbeitungsordner abgelegt. Nach Abschluss werden sie im Abgeschlossen-Ordner und wenn etwas schief gelaufen ist, werden diese Dateien im Fehlgeschlagen-Ordner gespeichert. Die Ordner befinden sich auf dem (S)FTP(S)-Server.
Entzippen und Entschlüsseln einbeziehen — Stellen Sie diese Option ein, wenn die Importdatei entzippt und entschlüsselt werden muss. Zum Assistenten wird ein zusätzlicher Schritt hinzugefügt, wenn diese Option ausgewählt ist.
Ordner
Legen Sie in diesem Abschnitt die Ordner fest, die auf dem Server verwendet werden sollen.
Verarbeitungsordner — Ordner, der vor Verarbeitung der Datei verwendet wird.
Abgeschlossen-Ordner — Ordner, der verwendet wird, wenn die Datei erfolgreich verarbeitet wurde.
Fehlgeschlagen-Ordner — Ordner, der verwendet wird, wenn die Verarbeitung fehlgeschlagen ist.
Entzippen und Entschlüsseln
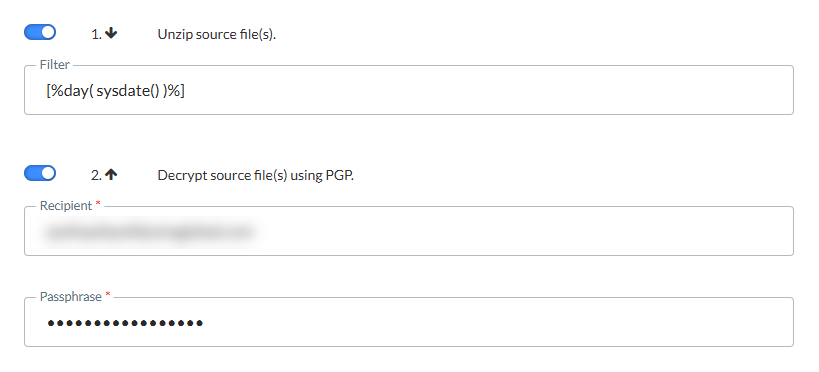
Wählen Sie die Optionen aus, die ausgeführt werden sollen, sowie die Reihenfolge, in der dies geschehen soll. Klicken Sie auf den Pfeil, um die Reihenfolge umzukehren.
Quelldateien entzippen — Wenn die Quelldatei gezippt ist, markieren Sie diese Option, um die Dateien zuerst zu entzippen. Verwenden Sie das Feld "Filter", um die Dateien zu filtern. Der Filter kann Ausdrücke enthalten. Klicken Sie auf das Personalisierungselement im Feld "Filter", um auf den Dialog zuzugreifen und den Ausdruck auszuwählen. Wichtig dabei ist, dass die Zip-Datei mit der Dateimaske übereinstimmt, die im Dateifilter auf der Registerkarte Quelle angegeben wurde.
Die folgenden Ausdrücke werden unterstützt:
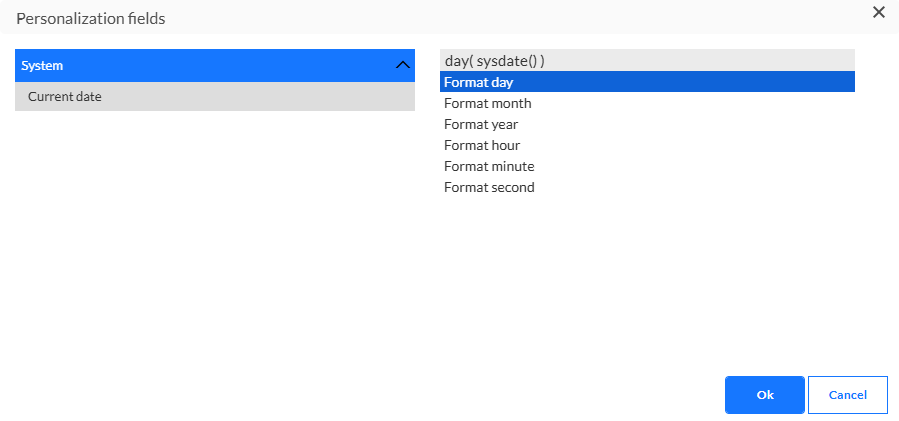
* [%year(sysdate())%]
* [%month(sysdate())%]
* [%day(sysdate())%]
* [%hour(sysdate())%]
* [%minute(sysdate())%]
* [%second(sysdate())%]
Quelldatei mithilfe von PGP entschlüsseln — Wenn die Quelldatei mit PGP verschlüsselt ist, muss der Benutzer die Passphrase und den Empfänger eingeben. Der Empfänger ist eine E-Mail-Adresse, die zum Abrufen des öffentlichen Schlüssels verwendet wird. Die Passphrase wird als Passwort für das Entschlüsseln verwendet.
Technischer Hinweis:
Um eine verschlüsselte Datei von einem externen Ort an die Selligent by Zeta-Plattform zu senden:
1. Verschlüsseln Sie die Datei mit dem öffentlichen Schlüssel, der von Selligent by Zeta zur Verfügung gestellt wurde.
2. Laden Sie die Datei auf den Selligent by Zeta (S)FTP(S)-Server hoch.
3. Konfigurieren Sie eine Import-Aufgabe, um diese Datei in die Selligent by Zeta-Plattform zu importieren.
- Aktivieren Sie in den Quelloptionen dieser Aufgabe die Option „Entpacken und Entschlüsseln aktivieren“.
- Tragen Sie im nächsten Schritt die Felder „Empfänger“ und „Passphrase“ die Werte ein, die mit Ihrem Selligent by Zeta PGP-Schlüssel verknüpft sind, um die Datei zu entschlüsseln.
Ziel definieren
In diesem Abschnitt definiert der Benutzer das Ziel der importierten Datei. Es muss ein temporärer Staging-Tabellenname angegeben werden.
Hinweis: Dies ist der Name einer temporären Tabelle, die zum Hochladen von Daten von der Quelle verwendet wird. Bei Verarbeitung jeder einzelnen Datei wird diese Tabelle gelöscht und neu erstellt. Denken Sie daran, wenn Sie Indizes, Constraints oder andere Dinge bei dieser Tabelle verwenden.
Spalte mit Benutzerkennung (MAID) einbeziehen — Markieren Sie die Option, um eine Spalte "MAID" hinzuzufügen, wenn wiederholte Importe erfolgen. Wenn dieses Kontrollkästchen aktiviert ist, wird eine zusätzliche Spalte "MAID" zu der Tabelle hinzugefügt, die vom Job-Agenten erstellt wird. Dies ist praktisch, um Datensätze in der Haupttabelle mit den entsprechenden Datensätzen der temporären Tabelle zu aktualisieren, da sie als Schlüsselfeld für eine Aktualisierung oder Einfügung verwendet wird.
Nachbearbeitung einbeziehen — Wenn diese Option markiert ist, haben Sie die Möglichkeit, eine gewisse zusätzliche Datenverarbeitung sowie Ablehnungsverwaltung durchzuführen. Zum Assistenten wird ein zusätzlicher Schritt hinzugefügt, um diese Extra-Optionen zu konfigurieren.
Nachbearbeitung
Datenverarbeitung

Wenn Datenverarbeitung erforderlich ist, aktivieren Sie die Option.
Klicken Sie auf die Bearbeiten-Schaltfläche, um das Stored Procedure auszuwählen. Der folgende Dialog wird angezeigt:
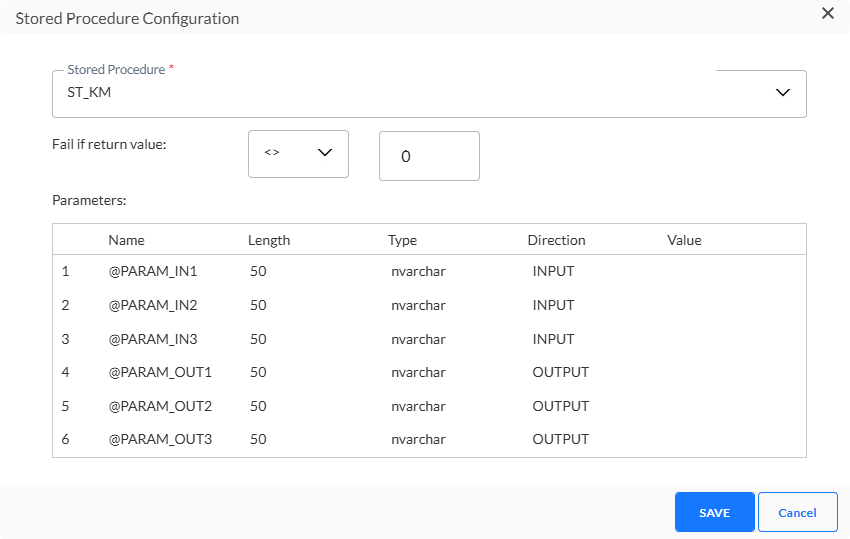
1. Wählen Sie aus der Dropdown-Liste das Stored Procedure aus, das zum Ausfüllen der Trigger-Datei verwendet wurde. Dies muss nicht dasselbe Stored Procedure wie für die Exportdatei sein.
2. Legen Sie als Nächstes das Fail-Constraint fest. Verwenden Sie den zurückgegebenen Wert des Stored Procedure, um zu definieren, ob es fehlgeschlagen ist oder nicht.
-
Wenn im Entwurf des Stored Procedure kein expliziter Rückgabewert definiert ist, wird im Erfolgsfall der Wert 0 standardmäßig zurückgegeben. Andere Werte implizieren einen Fehler.
In diesem Fall stellen Sie das Fail-Constraint wie folgt ein: Fehler, wenn Rückgabewert <> 0.
-
Wenn der Entwurf für das Stored Procedure ein oder mehrere benutzerdefinierte Rückgabewerte enthält, hängen die Werte, die bei Erfolg oder Fehler zurückgegeben werden, von diesem Entwurf ab.
In diesem Fall entscheiden Sie, was Sie als Fail-Constraint betrachten.Beispiel 1:
Das Stored Procedure, das verwendet wird, definiert, dass der Wert 10 nach Ausführung bestimmter SQL-Anweisungen zurückgegeben wird und der Wert 12 nach Ausführung eines anderen Satzes von SQL-Anweisungen zurückgegeben wird.
Sie betrachten den Teil, der den Rückgabewert als 12 definiert, als einzigen erfolgreichen Teil. In anderen Fällen sollte er als Fehler betrachtet werden.
In diesem Fall stellen Sie das Fail-Constraint wie folgt ein: Fehler, wenn Rückgabewert <> 12.Beispiel 2:
Das verwendete Stored Procedure definiert die Rückgabewerte 1, 10, 50, 51, 52, 53, 54, 55, 56, 60.
Sie betrachten die Rückgabewerte 1, 10 und 50 als „erfolgreiche“ Werte. Die anderen geben an, dass etwas falsch ist, und werden daher als Fehler betrachtet.
In diesem Fall können Sie das Fail-Constraint wie folgt einstellen: Fehler, wenn Rückgabewert >= 51.
3. Parameter – Einige Stored Procedures erfordern Parameter. Wenn dies der Fall wäre, ist ein zusätzlicher Abschnitt verfügbar, in dem diese Parameter definiert werden können.
Klicken Sie auf „Speichern“, um das ausgewählte Verfahren zu speichern.
Ablehnungsverwaltung
Ablehnungsverwaltung wird verwendet, wenn die Datenquelle validiert werden muss. Alle Datensätze, die nicht gültig sind, werden in eine getrennte Datei exportiert.

Basiskonzept:
- Daten werden in eine temporäre Datei übertragen.
- Zwei weitere Spalten (OPTI_REJECTED & OPTI_REJECTED_REASON) werden zur temporären Tabelle hinzugefügt.
- Das gespeicherte Verfahren führt Prüfungen bei den Daten durch. Wenn einige Datensätze beschädigte Informationen haben, muss die Spalte OPTI_REJECTED auf "1" gesetzt werden, was bedeutet, dass der Datensatz abgelehnt wird. Im Feld OPTI_REJECTED_REASON kann eine benutzerdefinierte Ablehnungsmeldung eingestellt werden.
Danach überträgt das gespeicherte Verfahren alle gültigen Daten aus der temporären Tabelle in die Selligent by Zeta-Tabelle.
Die Liste der möglichen Medientypen umfasst Repository, Autorisierte URL, Öffentliche URL, Azure Blob-Speicher, Amazon S3-Speicher, Google Cloud-Speicher, FTP, SFTP, FTPS. Die auszufüllenden Parameter hängen vom ausgewählten Medientyp ab. Die auszufüllenden Parameter hängen vom ausgewählten Medientyp ab. Der Benutzer kann einen Unterordner zum Speichern der Datei auswählen. Der Dateityp wird standardmässig durch ; getrennt.
Repository — Der Server, auf dem der Prozess ausgeführt wird, enthält ein lokales Dateisystem, in dem sich bereits zwei Ordner befinden: Dateneingang und Campaign-Daten. Sie können einen Unterordner auswählen, aus dem die Importdatei abgerufen wird.
Öffentliche URL — Geben Sie die URL an. Zugänglich ohne Anmeldung und Passwort und unterstützt HTTP und HTTPS.
Autorisierte URL — Geben Sie die URL und den Benutzernamen und das Passwort für das Verbinden an. Unterstützt nur HTTPS.
Azure Blob-Speicher — Geben Sie die Verbindungszeichenfolge (Sie können die Sichtbarkeit der Zeichenfolge durch Klicken auf das Augensymbol ein- und ausschalten) und den Container und einen optionalen Unterordner an. (*)
Amazon S3-Speicher — Geben Sie die ID des Zugriffsschlüssels und den geheimen Zugriffsschlüssel (Sie können die Sichtbarkeit beider Zeichenfolgen durch Klicken auf das Augensymbol ein- und ausschalten), den Bucket-Namen, den Code des Regionsendpunkts und einen optionalen Unterordner an. (*)
Google Cloud-Speicher — Geben Sie den Typ, die Projekt-ID, die ID des privaten Schlüssels und den privaten Schlüssel (Sie können die Sichtbarkeit beider Zeichenfolgen durch Klicken auf das Augensymbol ein- und ausschalten), die Client-E-Mail, die Client-ID, die Auth-URI, die Token-URI, die URL des Authprovider X509-Zertifikats, die URL des Client X509-Zertifikats, den Bucket-Namen und einen optionalen Unterordner an. (*)
* Hinweis: Details dazu, wie Cloud-Speicherkonfigurationen eingerichtet werden, sind hier zu finden.
Vordefiniert — Beim Auswählen dieser Option wird das Feld „Vordefiniertes Transportmedium“ angezeigt, in dem Sie ein Medium aus einer Liste vordefinierter Medien auswählen können. Diese Medien sind bereits in der Admin-Konfiguration konfiguriert und mit Ihrem Geschäftsbereich verknüpft. Wenn Sie eines auswählen, werden alle entsprechenden Einstellungen verwendet.
FTPS, FTPS implizit, SFTP — Geben Sie den Namen des Servers und den Benutzer und das Passwort für das Verbinden mit dem Server an. Es kann ein Unterordner auf dem Server ausgewählt werden. Standardmässig ist ein Unterordner ausgefüllt.
Hinweis: Neben der Passwortauthentifizierung ist es möglich, stattdessen die Authentifizierung mit einem privaten Schlüssel zu verwenden. Weitere Informationen finden Sie in diesem Abschnitt oben.
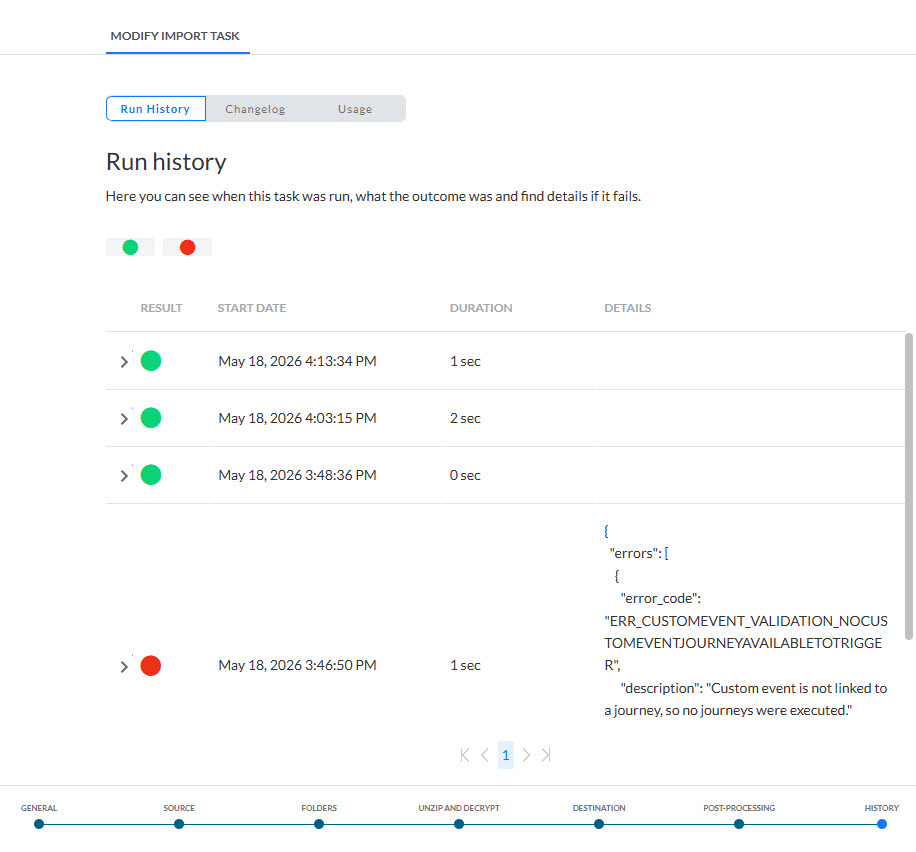
Verlauf
Der Verlauf liefert Informationen darüber,
- wann diese Aufgabe geändert (aktualisiert, gelöscht) wurde und von wem. Diese Information ist auf der Registerkarte „Änderungsprotokoll“ verfügbar.
- wann die Aufgabe ausgeführt wurde, sowie der Status dieser Ausführung. Diese Informationen sind auf der Registerkarte „Ausführungsverlauf“ verfügbar. Wenn die Aufgabe Teilaufgaben umfasst, kann der Ausführungsverlauf dieser Aufgaben ebenfalls eingesehen werden.
- wo die Aufgabe verwendet wird. Diese Informationen sind auf der Registerkarte „Nutzung“ verfügbar.
Verwenden Sie die Filtersymbole oben, um den Ausführungsverlauf zu filtern.