
Ein Import kann auf zwei Arten erstellt werden:
- Vom Flyout-Menü aus, das vom Eintrag 'Datenaustausch' in der linken Navigationsleiste verfügbar ist. Klicken Sie auf die Schaltfläche Neu und wählen Sie Datenimport aus der Dropdown-Liste aus.
- Wählen Sie im Importe/Exporte-Start Seite 'Neu > Datenimport ' aus. Ein Assistent führt Sie durch den Erstellungs- und Konfigurationsvorgang.
Geplanten Datenimport erstellen
- Eigenschaften festlegen
- Planungs- und Benachrichtigungsoptionen einstellen
- Benachrichtigungen
- Terminplaner einstellen (Optional)
- Eigenschaften festlegen
- Planungs- und Benachrichtigungsoptionen einstellen
- Benachrichtigungen
- Terminplaner einstellen (Optional)
Geplanten Datenimport erstellen
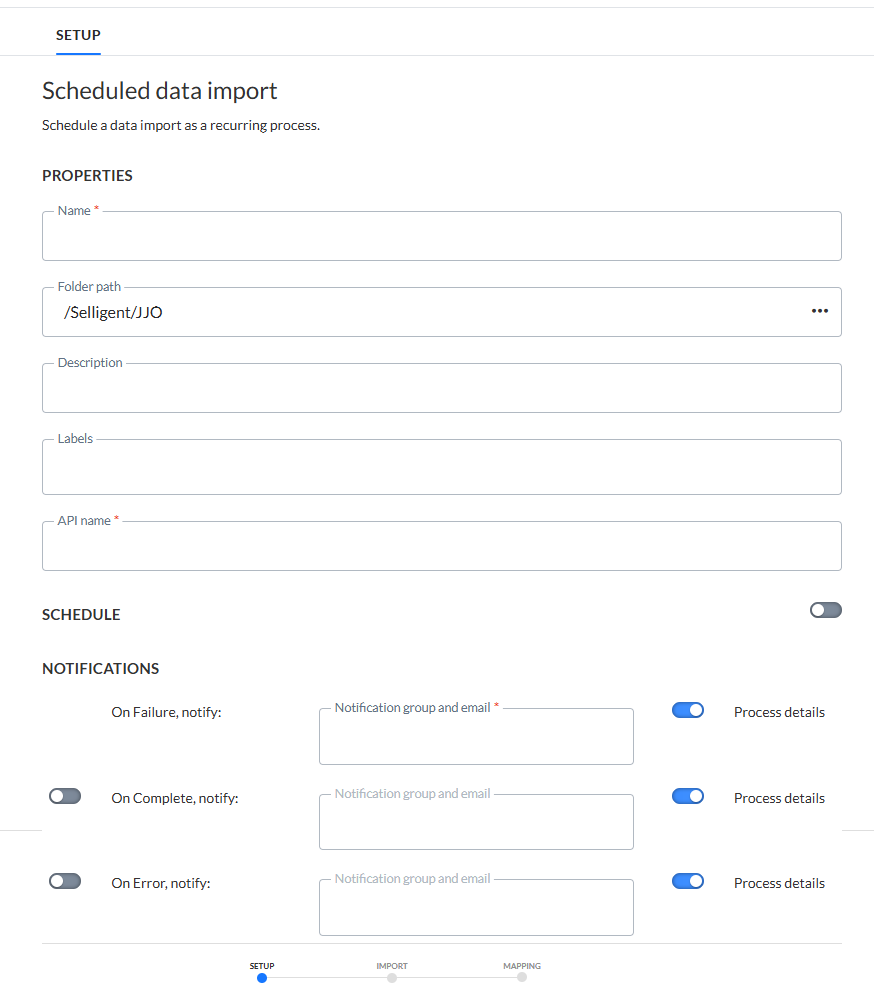
Eigenschaften festlegen
-
Ordnerpfad — Legen Sie den Ordnerpfad für diesen Import fest. Dies ist der Ort in der Ordnerstruktur, an dem der Import gespeichert ist.
-
Namen und Beschreibung — Dieser sollte möglichst eindeutig sein, um der Import im Start Seite leicht erkennen zu können.
-
API-Namen — Der Name wird verwendet, wenn der Import über die API ausgeführt wird. Standardmäßig wird der API-Name mit dem Namen ausgefüllt, der dem Import gegeben wurde.
-
Komponenten-Labels – Das (die) dieser Komponente zugewiesene(n) Label(s). Wählen Sie ein oder mehrere Labels aus der Dropdown-Liste. (Diese Labels werden in der Admin-Konfiguration konfiguriert). Benutzer mit der entsprechenden Zugriffsberechtigung können hier auch neue Labels erstellen, indem sie den neuen Label-Wert in das Feld eingeben.
Planungs- und Benachrichtigungsoptionen einstellen
Im Abschnitt "Plan' werden die Gültigkeitsdauer für den Import sowie die Häufigkeit der Ausführung definiert.
Wenn der Import geplant werden muss, schalten Sie die Option ein und definieren Sie den Plan.
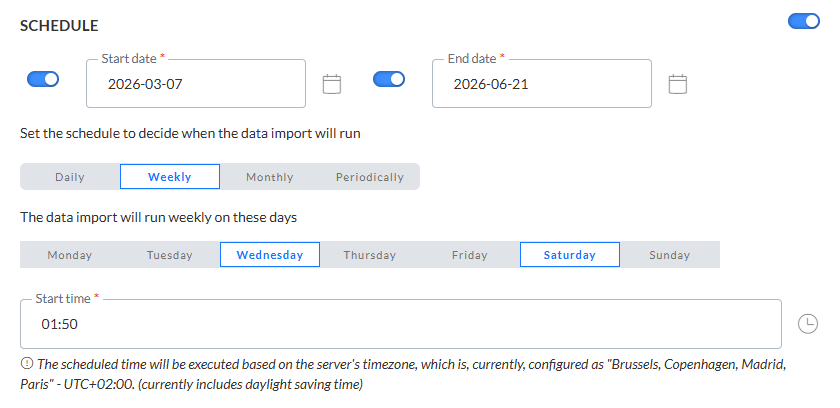
Start- und Enddatum — Sie können ein Startdatum und/oder Enddatum für den Import einstellen. Zum Beispiel kann Ihr Import jetzt starten, muss aber unendlich laufen.
Häufigkeit — Geben Sie an, wann der Import ausgeführt werden soll:
- Täglich — Wählen Sie die Stunden des Tages aus, in denen der Import ausgeführt werden soll. Sie können mehr als eine auswählen.
- Wöchentlich — Wählen Sie die Tage der Woche aus, an denen der Import ausgeführt werden soll. Der Import kann mehr als einmal die Woche ausgeführt werden. Sie können auch die Startzeit festlegen.
- Monatlich — Wählen Sie die Tage des Monats aus, an denen der Import ausgeführt werden soll. Sie können auch die Tageszeit auswählen, zu der der Import starten soll.
- Periodisch — Legen Sie das erneute Erfolgen des Imports, in Minuten ausgedrückt, fest. Der Import wird zum Beispiel alle 10 Minuten ausgeführt.
Hinweis: Die geplante Zeit wird auf Basis der Zeitzone des Servers ausgeführt. Die zurzeit konfigurierte Zeitzone des Servers wird neben dem Info-Symbol angezeigt.
Benachrichtigungen
Es kann auch eine Nachricht gesendet werden
- * OnFailure — Bei Fehlschlagen des Prozesses Es ist mindestens eine E-Mail-Adresse erforderlich. This can happen when there is a data mismatch, a column number mismatch between source and target, etc.
- OnComplete — Bei erfolgreichem Abschluss der Aufgabe
- OnError — Mit Fehlern abgeschlossen (Auftrag wurde abgeschlossen, aber eine oder mehrere Aufgaben führte/n zu Fehlern/Ausnahmen)
- OnNoFile — Wenn keine Datei gefunden werden konnte
Die Details des Vorgangs können in die Nachricht einbezogen werden. Ausserdem wird die Instanz, bei der das Problem aufgetreten ist, in den Betreff der Nachricht einbezogen.
Um die Option zu aktivieren, aktivieren Sie einfach den Umschalter auf der linken Seite und geben Sie eine oder mehrere E-Mail-Adressen ein. (Mehrere E-Mail-Adressen werden durch ein Semikolon getrennt.) Sie können auch eine Benachrichtigungsgruppe auswählen. Benachrichtigungsgruppen werden in der Admin-Konfiguration erstellt.
Hinweis: Die Angabe einer oder mehrerer Benachrichtigungsgruppen/E-Mail-Adressen für den Fall, dass der [Import][Export] fehlschlägt, ist obligatorisch. Die anderen Benachrichtigungen (bei Abschluss oder Fehler) sind optional.
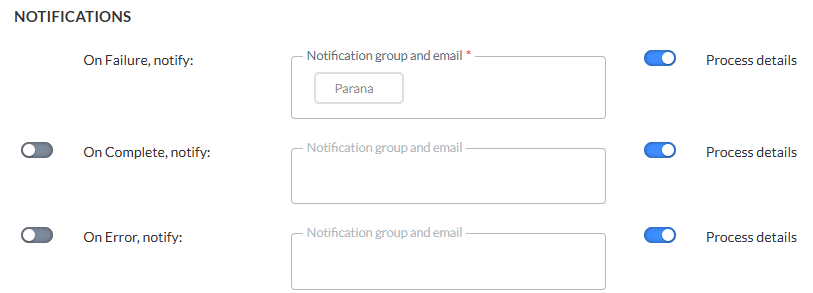
Klicken Sie, wenn Sie fertig sind, auf Weiter.
Terminplaner einstellen (Optional)
Hinweis: Der Terminplaner-Abschnitt ist nur sichtbar, wenn Terminplaner für Ihre Umgebung konfiguriert sind. Standardmäßig gibt es 1 Terminplaner. In diesem Fall wird dieser Abschnitt nicht angezeigt, da dieser Standard-Terminplaner verwendet wird. Wenn mehr als 1 Terminplaner konfiguriert ist, haben Sie Zugriff auf den Terminplaner-Abschnitt.
Wenn mehrere Aufgaben, Importe oder Exporte laufen, kann es eine gute Idee sein, einen unterschiedlichen Terminplaner zu verwenden, um sicherzustellen, dass lang laufende Aufgaben kleinere Aufgaben nicht stören. Das Auswählen eines Terminplaners ist optional, und wenn Sie den voreingestellten behalten, werden alle Aufgaben/Exporte/Importe trotzdem ausgeführt, aber wenn es eine größere Aufgabe gibt, wird die kleinere nur ausgeführt, wenn die größere beendet ist.

Sie können zwischen 3 verschiedenen Terminplanern auswählen: dem voreingestellten, dem benutzerdefinierten Terminplaner 1 und dem benutzerdefinierten Terminplaner 2. Wenn Sie verschiedene Terminplaner für Ihre Aufgaben auswählen, werden sie parallel ausgeführt, ohne einander zu stören. Wenn Sie also länger laufende Aufgaben haben, kann es eine gute Idee sein, diese mit einem anderen Terminplaner auszuführen.
Importoptionen einstellen
Liste auswählen
Liste — Wählen Sie aus dem Dropdown die Liste aus, in die die Datensätze importiert werden sollen. Dies können eine Zielgruppenliste, Datenliste, Optionsliste, Datenauswahlliste oder benutzerdefinierte Ereignisse sein.
Zum Import in eine benutzerdefinierte Ereignisliste müssen Sie zuerst die Zielgruppenliste auswählen. Ein Schalter ermöglicht die Aktivierung des Imports in benutzerdefinierte Ereignisse. Alle mit der ausgewählten Zielgruppenliste verknüpften benutzerdefinierten Ereignisse sind im Dropdown unter dem Schalter aufgelistet:
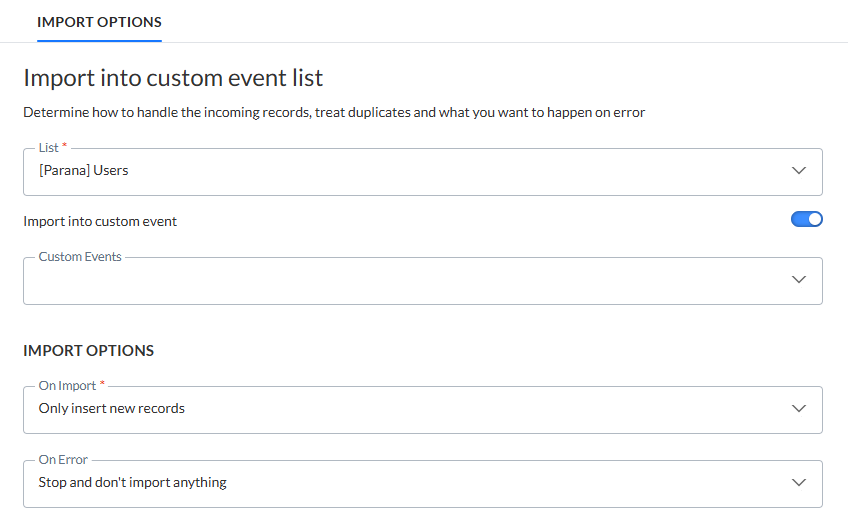
Hinweis: Wenn die Liste geändert wird, nachdem die Feldzuordnung definiert wurde, wird eine Benachrichtigung angezeigt, die Sie darauf hinweist, dass alle Spaltenzuordnungen verloren gehen, wenn Sie fortfahren. Sie können die Änderung rückgängig machen, indem Sie auf den entsprechenden Link „Rückgängig machen“ klicken und die Zielgruppe auf die zuvor ausgewählte Zielgruppe zurücksetzen.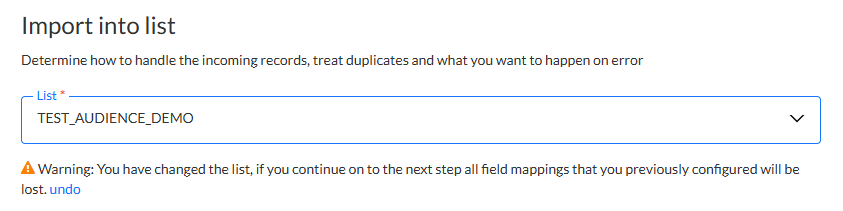
Importoptionen definieren
Beim Importieren in eine Liste oder ein Segment, die/das bereits Datensätze enthält, müssen Sie definieren, was beim Import passieren muss.
Beim Import
- Neue Datensätze einfügen und vorhandene Datensätze aktualisieren (nur für Import in Listen, nicht Segmente) Für den Import in benutzerdefinierte Ereignisse können nur neue Datensätze hinzugefügt werden, keine Aktualisierung vorhandener Datensätze.
- Nur neue Datensätze einfügen — Bestehende Datensätze werden nicht aktualisiert, es werden lediglich neue Datensätze erstellt.
- Nur vorhandene Datensätze aktualisieren — Es werden keine neuen Datensätze eingefügt (nur für Import in Listen, nicht Segmente).
- Vorhandene Datensätze löschen — Nur wenn eine übereinstimmung mit einem Datensatz in der Liste gefunden wird, wird der Datensatz gelöscht. Es werden keine anderen Datensätze aktualisiert oder eingefügt.
Hinweis: Die Option „Vorhandene Datensätze löschen“ kann nicht in Kombination mit einem Import in einer Liste mit 1:1-Verknüpfung oder beim Transformieren von Werten über umgekehrte Recherche verwendet werden.
Beim Duplizieren von Daten (nur für Listen, nicht Segmente oder benutzerdefinierte Ereignisse
- Erste übereinstimmung importieren — Wenn doppelte Datensätze gefunden werden, wird der erste Datensatz, der mit einem vorhandenen Datensatz übereinstimmt, importiert. Alle folgenden Datensätze, die mit dem vorhandenen Datensatz übereinstimmen, werden nicht importiert.
- Letzte übereinstimmung importieren — Wenn doppelte Datensätze gefunden werden, wird der letzte Datensatz, der mit einem vorhandenen Datensatz übereinstimmt, importiert.
Bei Fehler – Definiert das Verhalten des Importvorgangs, wenn ein fehlerhafter Datensatz gefunden wird. Optionen sind:
- Stoppen und nichts importieren – Wenn ein Problem in einer Datei auftritt, bricht diese Option die Verarbeitung der aktuellen Datei ab und erzeugt eine Benachrichtigung an die OnFailure-Adresse. Vorherige Dateien werden während dieser Aufgabe möglicherweise trotzdem erfolgreich importiert.
- Import fortsetzen – Ignoriert den fehlerhaften Datensatz und setzt die Verarbeitung fort, wobei schließlich eine Benachrichtigung an die OnComplete-Adresse gesendet wird, wenn dies in den Benachrichtigungen eingestellt ist.
Beispiele von Fehlern:
- Unzureichende Anzahl von Spalten (erwartet 5, gefunden 3)
- Daten zu lang für den Listendatentyp (55 Zeichen für ein Textfeld von 50 Zeichen)
- Nicht übereinstimmende Datentypen (Text, wenn Zahl erwartet wird)
- Unsinnige Daten (z. B. 1975-13-37)
Hinweis: Bei Auftreten einer leeren Datei wird die Datenimportroutine abgebrochen, selbst wenn „Import fortsetzen“ ausgewählt ist.
Beispiel:
A.csv (10 gute Datensätze)
B.csv (10 gute Datensätze)
C.csv (10 Datensätze, von denen Datensatz 5 und 7 beschädigt sind)
D.csv (10 gute Datensätze)
Wenn die Option „Stoppen und nichts importieren“ aktiviert ist, werden 20 Datensätze aus Dateien A und B verarbeitet. Die ersten 4 Datensätze aus Datei C werden nicht verarbeitet und Datei D wird ebenfalls nicht verarbeitet.
Wenn die Option „Import fortsetzen“ aktiviert ist, werden alle Datensätze in allen Dateien verarbeitet, mit Ausnahme der 2 beschädigten Datensätze in Datei C.
Technischer Hinweis: Da Dateien in lexikalischer Reihenfolge verarbeitet werden (zb. 1, 10, 100, 2, 33, 4, 500 ), wird empfohlen, wenn die Reihenfolge, in der Dateien verarbeitet werden, wichtig ist, ein Datum oder eine Sequenznummer im Dateinahme zu verwenden. Wenn die Verarbeitungsreihenfolge wichtig ist, wird außerdem empfohlen, die Option „Import fortsetzen“ nicht zu verwenden.
Quelle definieren
Medium — Die Liste der möglichen Medientypen umfasst Repository, Autorisierte URL, Öffentliche URL, Azure Blob-Speicher, Amazon S3-Speicher, Google Cloud-Speicher, FTP, SFTP, FTPS. Die einzugebenden Parameter hängen vom ausgewählten Medientyp ab. Die einzugebenden Parameter hängen vom ausgewählten Medientyp ab. Der Benutzer kann einen Unterordner zum Speichern der Datei auswählen. Der Dateityp wird standardmässig durch ; getrennt.
- Repository — Der Server, auf dem der Prozess ausgeführt wird, enthält ein lokales Dateisystem, das bereits zwei Ordner enthält: Dateneingang und Campaign-Daten. Sie können einen Unterordner auswählen, aus dem die Importdatei abgerufen wird.
- Öffentliche URL — Geben Sie die URL an. Zugänglich ohne Anmeldung und Passwort und unterstützt HTTP und HTTPS.
- Autorisierte URL — Geben Sie die URL und den Benutzernamen und das Passwort für das Verbinden an. Unterstützt nur HTTPS.
- Azure Blob-Speicher – Geben Sie die Verbindungszeichenfolge (Sie können die Sichtbarkeit der Zeichenfolge durch Klicken auf das Augensymbol ein- und ausschalten) und den Container und einen optionalen Unterordner an. (*)
- Amazon S3-Speicher — Geben Sie die ID des Zugriffsschlüssels und den geheimen Zugriffsschlüssel (Sie können die Sichtbarkeit beider Zeichenfolgen durch Klicken auf das Augensymbol ein- und ausschalten), den Bucket-Namen, den Code des Regionsendpunkts und einen optionalen Unterordner an. (*)
- Google Cloud-Speicher — Geben Sie den Typ, die Projekt-ID, die ID des privaten Schlüssels und den privaten Schlüssel (Sie können die Sichtbarkeit beider Zeichenfolgen durch Klicken auf das Augensymbol ein- und ausschalten), die Client-E-Mail, die Client-ID, die Auth-URI, die Token-URI, die URL des Authprovider X509-Zertifikats, die URL des Client X509-Zertifikats, den Bucket-Namen und einen optionalen Unterordner an. (*)
* Hinweis: Details dazu, wie Cloud-Speicherkonfigurationen eingerichtet werden, sind hier zu finden.
- Vordefiniert — Beim Auswählen dieser Option wird das Feld "Vordefiniertes Transportmedium' angezeigt, in dem Sie ein Medium aus einer Liste vordefinierter Medien auswählen können. Diese Medien sind bereits in der Admin-Konfiguration konfiguriert und mit Ihrem Geschäftsbereich verknüpft. Wenn Sie eines auswählen, werden alle entsprechenden Einstellungen verwendet. (*)
- FTPS, FTPS implizit, SFTP — Geben Sie den Namen des Servers und den Benutzernamen und das Passwort für das Verbinden mit dem Server an. Es kann ein Unterordner auf dem Server ausgewählt werden. Standardmässig wird ein Unterordner eingegeben.
Hinweis: Wenn ein Datenimport ausgeführt wurde, wird die Datei automatisch vom FTP entfernt..
Dateifilter — Ist standardmässig auf * eingestellt. Sie können dieses Feld verwenden, um die Dateien auf dem ausgewählten Medium entsprechend diesen Filterkriterien zu filtern (z. B. *.txt).
Authentifizierung mit privatem Schlüssel
Bei SFTP kann neben der Verwendung eines Passworts zur Authentifizierung bei der Verbindung mit dem Server auch ein privater Schlüssel verwendet werden:
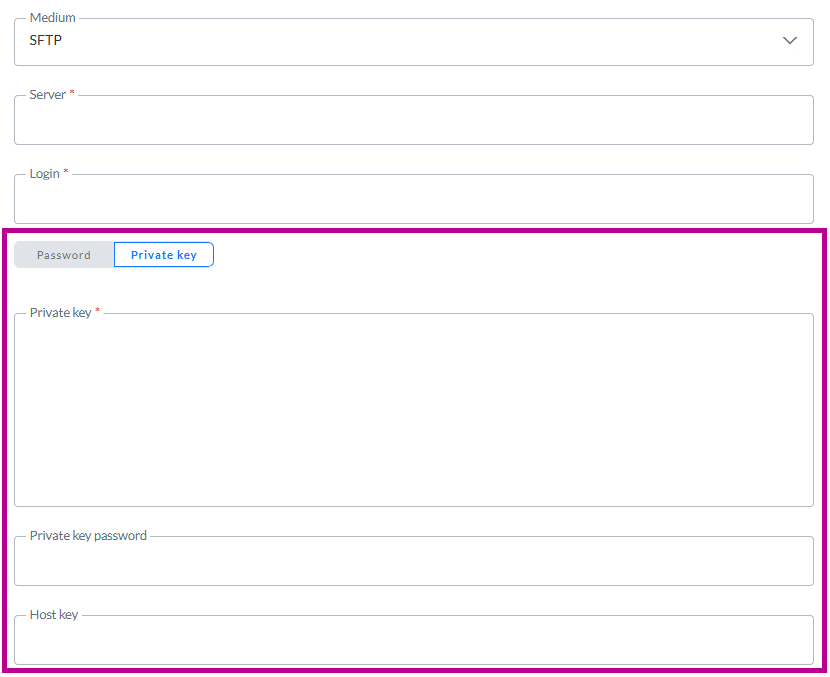
Mit einem Umschalter können Sie entweder Passwort oder Privater Schlüssel auswählen. Wenn Privater Schlüssel ausgewählt ist, können Sie die Daten des privaten Schlüssels in das Feld Privater Schlüssel eingeben (oder mit Copy und Paste einfügen).
Wenn für den privaten Schlüssel ein Passwort erforderlich ist (bei einigen Servern ist dies der Fall), können Sie das Passwort in das Feld Passwort für den privaten Schlüssel eingeben. Dies ist ein optionales Feld.
HinweisDie Daten aus beiden Feldern (privater Schlüssel und Passwort für den privaten Schlüssel) werden verschlüsselt in der Datenbank gespeichert und nur bei der Übertragung der Dateien verwendet
Der Host-Schlüssel ist ein optionales Feld, das als zusätzlicher Überprüfungsschritt verwendet werden kann, um sicherzustellen, dass Sie sich mit dem richtigen Server verbinden.
HinweisBeim Speichern der/des [Importaufgabe/Datenimports/Exportaufgabe/Datenexports/Mediums]:
– Der Inhalt des Feldes für den privaten Schlüssel wird geleert (aus Sicherheitsgründen)
– Das Label des Feldes für den privaten Schlüssel wird auf Einen neuen privaten Schlüssel angeben, um den vorhandenen privaten Schlüssel zu aktualisieren aktualisiert
– Der Inhalt des Feldes für das Passwort des privaten Schlüssels wird geleert (aus Sicherheitsgründen)
– Das Label des Feldes für das Passwort des privaten Schlüssels wird auf Ein neues Passwort für den privaten Schlüssel angeben, um den vorhandenen privaten Schlüssel zu aktualisieren aktualisiert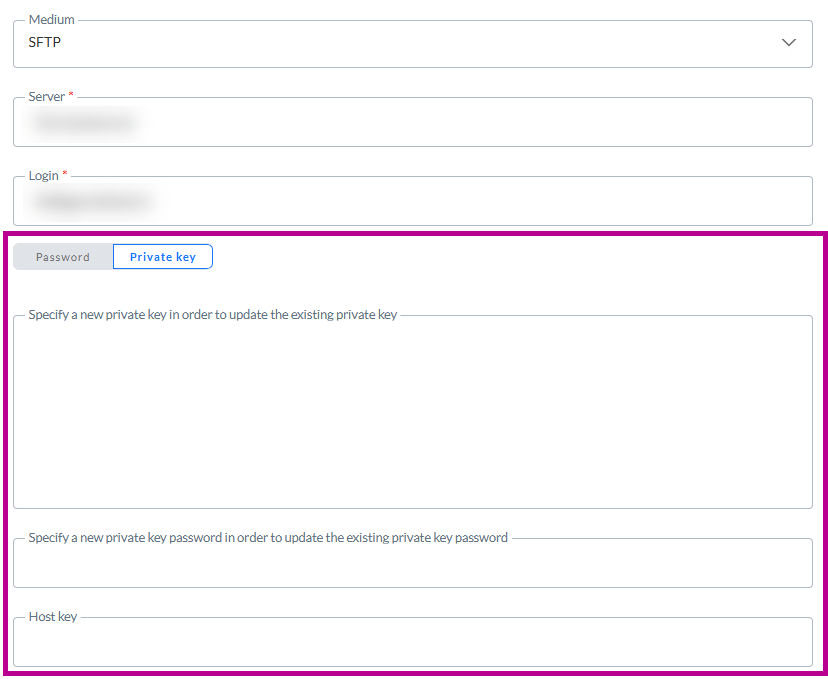
Dateioptionen definieren

Sie haben die Auswahl zwischen:
- Getrennt — Dateien mit Trennzeichen sind Dateien, die Komma, Semikolon, Pipe oder Tabulator als Trennzeichen für Spalten verwenden.
- Excel (XLS) — Eine Excel-Datei mit oder ohne Zeilenüberschriften kann als Importdatei verwendet werden. Hier können XLS und XLSX verwendet werden.
- RSS — Der Rootknoten der RSS-Datei muss angegeben werden.
Getrennt
Klicken Sie auf das Stiftsymbol, um auf den Dialog „Dateioptionen“ zuzugreifen.:
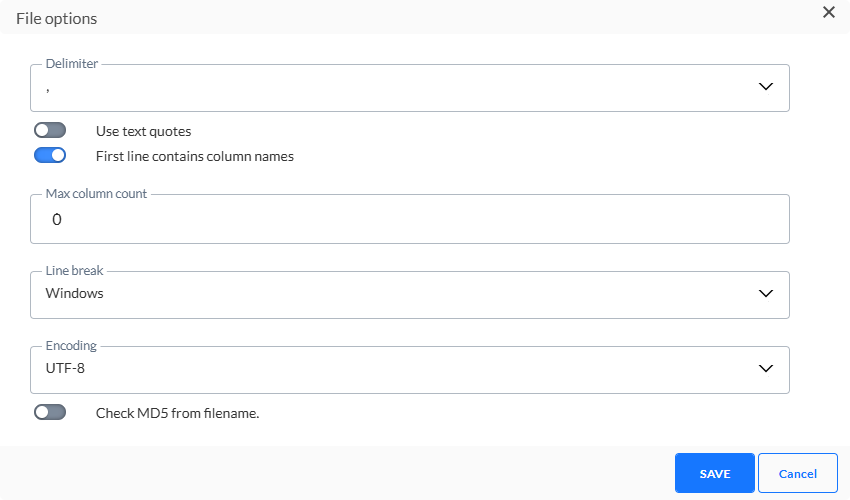
- Das Dateitrennzeichen kann auf Doppelpunkt, Strichpunkt, Tabulator oder Pipe-Zeichen eingestellt werden. Standardmässig ist das Trennzeichen auf ; eingestellt.
- Ein Einschliessen des Texts mit Anführungszeichen ist möglich. Schalten Sie die Option ein, wenn Sie dies möchten. Beachten Sie jedoch, dass Zeilenschaltungen nicht unterstützt werden;
- Sie können ausserdem die erste Zeile als diejenige festlegen, die die Spaltennamen enthält. Diese Option ist standardmässig auswählt.
- Legen Sie die Art der Codierung fest, die auf die Datei angewandt werden soll. Klicken Sie auf die Dropdown-Liste, um auf eine umfassende Liste von Codiermechanismen zuzugreifen.
- Max. Spaltenzahl - Die maximale Anzahl der in der Datei zulässigen Spalten
- Codierung – Legen Sie die Art der Codierung fest, die auf die Datei angewandt werden soll. Klicken Sie auf die Dropdown-Liste, um auf eine umfassende Liste von Codiermechanismen zuzugreifen.
- MD5 aus Dateiname prüfen – Diese Option wird verwendet, um den Inhalt der Datei zu überprüfen. Dieser MD5-Schlüssel wird zum Dateinamen hinzugefügt und auf Basis des Inhalts der Datei erstellt. Wenn diese Option aktiviert ist, wird der MD5-Schlüssel gegenüber dem Inhalt der Datei geprüft und dies ermöglicht die Erkennung von Änderungen in der Datei.
- Zeilenumbruch – Stellen Sie den Zeilenumbruch entweder auf Windows oder Unix ein. Windows verwendet Carriage Return und Line Feed („\r\n“) als Zeilenende, während Unix nur Line Feed („\n“) verwendet.
Excel (XLS)
Klicken Sie auf das Stiftsymbol, um auf den Dialog „Dateioptionen“ zuzugreifen.
Blattname – Der Name des Blatts in der xls-Datei für den Import.Wenn mehrere Arbeitsblätter vorliegen, wird nur das benannte Arbeitsblatt verarbeitet, alle anderen Arbeitsblätter werden ignoriert. Falls mehrere Arbeitsblätter zu verarbeiten sind, müssen sie als einzelne XLSX-Dateien behandelt werden, da jeweils nur ein Arbeitsblatt importiert werden kann.
Die erste Zeile enthält Spaltennamen – Wählen Sie die Option aus, wenn die oberste Zeile in Ihrem Blatt den Spaltennamen enthält.
Zu überspringende Zeilen – Geben Sie die Nummern der Zeilen in der Datei an, die ausgeschlossen werden sollen.
Codierung – Legen Sie die Art der Codierung fest, die auf die Datei angewandt werden soll. Vom Dropdown aus können Sie auf eine umfassende Liste von Codiermechanismen zugreifen.
Außerdem wird „MD5 aus Dateiname prüfen“ verwendet, um den Inhalt der Datei erneut zu prüfen. Dieser MD5-Schlüssel wird zum Dateinamen hinzugefügt und auf Basis des Inhalts der Datei erstellt. Wenn diese Option aktiviert ist, wird der MD5-Schlüssel gegenüber dem Inhalt der Datei geprüft und dies ermöglicht die Erkennung von Änderungen in der Datei
RSS
Klicken Sie auf das Stiftsymbol, um auf den Dialog „Dateioptionen“ zuzugreifen.
Rootknoten (optional) — Der Rootknoten, von dem alle untergeordneten Knoten abgerufen werden. Wenn der Rootknoten nicht konfiguriert ist, ist der voreingestellte Xpath, in dem Daten erwartet werden, der Channel Knoten. Wenn der Rootknoten konfiguriert ist, können Sie diesen Namen verwenden.
Hinweis: Alle <item>-Elemente und ihr Inhalt innerhalb des Rootknotens (z. B. <channel>) können importiert werden. Wenn andere Elemente direkt unter dem Root-Element erscheinen (auf derselben Ebene wie <item>-Elemente), werden diese nicht importiert.
Beispiel 1 — Wenn wir keinen Rootknoten konfigurieren, wird der Knoten „channel“ aus dieser RSS-Datei standardmäßig als Rootknoten verwendet (das Element und seine Details werden importiert):
<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<item>
<title>News of today</title>
<link>https://www.xul.fr/en-xml-rss.html</link>
<description>RSS item 1</description>
<name>Siyashree</name>
</item>
</channel>
</rss>Beispiel 2 — Wir konfigurieren ein „customrss“-Element als Rootknoten. Es wird als Root in der folgenden RSS-Datei verwendet (das Element und seine Details werden importiert):
<?xml version="1.0" ?>
<rss version="2.0">
<customrss>
<item>
<title>News of today</title>
<link>https://www.xul.fr/en-xml-rss.html</link>
<description>RSS item 1</description>
<name>Siyashree</name>
</item>
</customrss>
</rss>Codierung — Legen Sie die Art der Codierung fest, die auf die Datei angewandt werden soll. Klicken Sie auf die Dropdown-Liste, um auf eine umfassende Liste von Codiermechanismen zuzugreifen.
MD5 aus Dateiname prüfen — Diese Option wird verwendet, um den Inhalt der Datei erneut zu prüfen. Dieser MD5-Schlüssel wird zum Dateinamen hinzugefügt und auf Basis des Inhalts der Datei erstellt. Wenn diese Option aktiviert ist, wird der MD5-Schlüssel gegenüber dem Inhalt der Datei geprüft und dies ermöglicht die Erkennung von Änderungen der Datei.
Hinweis: Bei der Verwendung von RSS-Dateien wird standardmäßig Media RSS* unterstützt
* Was ist Media RSS? Es handelt sich um eine RSS-Erweiterung, die mehrere Verbesserungen für RSS-Anhänge hinzufügt und für die Syndication von Multimedia-Dateien in RSS-Feeds verwendet wird. Ursprünglich wurde es 2004 von Yahoo! und der Media-RSS-Gemeinschaft entwickelt, aber 2009 wurde seine Entwicklung an das RSS Advisory Board übertragen.
Bitte konsultieren Sie https://www.rssboard.org/media-rss für weitere Informationen.
Beispiel für eine RSS-Datei mit Medieninhalten (MRSS):
<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<item>
<title>The latest video from artist XYZ</title>
<link>http://www.foo.com/item1.htm</link>
<artist>XYZ</artist>
<media:content url="http://www.foo.com/movie.mov" type="video/quicktime" />
<media:keywords><![CDATA[XYZ, album, song, year]]></media:keywords>
<media:thumbnail url="http://www.foo.com/XYZ.jpg" width="98" height="98"></media:thumbnail>
</item>
</channel>
</rss>Den Abgleich der Felder für dieses Media-RSS-Beispiel finden Sie hier.
Feldabgleich definieren
Definieren Sie den Abgleich zwischen den Feldern in der Importdatei und den Feldern in der Selligent Liste.
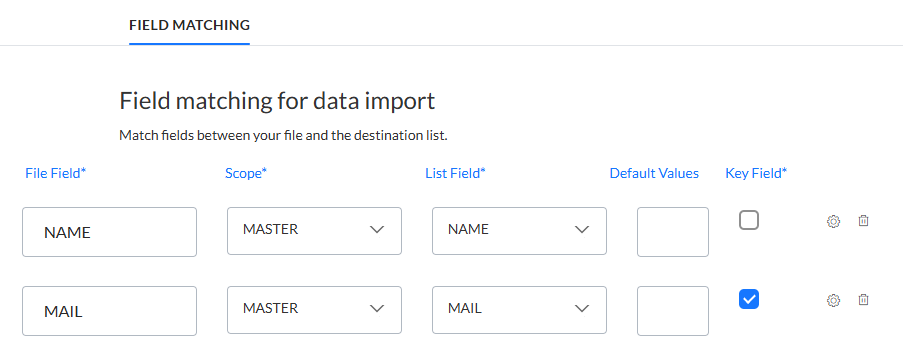
Dateifeld — Geben Sie den Namen des Felds in der Importdatei ein.
Liste — Diese Spalte ist nur beim Durchführen eines Imports in eine Zielgruppenliste verfügbar. Sie ermöglicht den Import in Listen mit 1:1-Verknüpfung für die ausgewählte Zielgruppe. Wählen Sie die Liste mit 1:1-Verknüpfung aus, in die Daten aus der Quelldatei importiert werden müssen.
Hinweis: Wenn die Option „Vorhandene Datensätze löschen“ in den Importeigenschaften ausgewählt ist, ist es nicht möglich, einen Import in eine Liste mit 1:1-Verknüpfung durchzuführen.
Wenn ein Import in eine Liste mit 1:1-Verknüpfung durchgeführt wird, sind diese Informationen außerdem in der Nutzungsübersicht der verknüpften Liste verfügbar und die verknüpfte Liste kann nicht gelöscht werden.
Listenfeld — Wählen Sie ein Feld in der Zielgruppenliste aus dem Dropdown aus.
Hinweis: Beim Importieren in eine benutzerdefinierte Ereignisliste ist es nicht möglich, Werte in das Feld „Zustand“ zu importieren. Dies ist ein Systemfeld und kann während des Imports nicht verwendet werden.
Standard Wert — Es ist möglich, einen Standardwert für ein gemapptes Selligent-Feld zu definieren. Dadurch wird sichergestellt, dass, wenn in der Quelle kein Wert gefunden wird, der Standardwert verwendet und im Selligent-Feld gespeichert wird. Dies kann der Fall sein, wenn das Quellfeld keinen Wert für einen Datensatz enthält, oder wenn das im Mapping verwendete Quellfeld einfach nicht vorhanden ist.
Schlüsselfeld — Markieren Sie die Option des ausgewählten Felds, das als Schlüsselfeld verwendet wird.
Hinweis: Wenn das ID-Feld in der Zielgruppenliste als Schlüsselfeld verwendet wird, können Datensätze nur aktualisiert werden. Es werden keine Einfügungen durchgeführt.
Für das hier erwähnte Media-RSS-Beispiel könnte der Feldabgleich wie folgt aussehen:
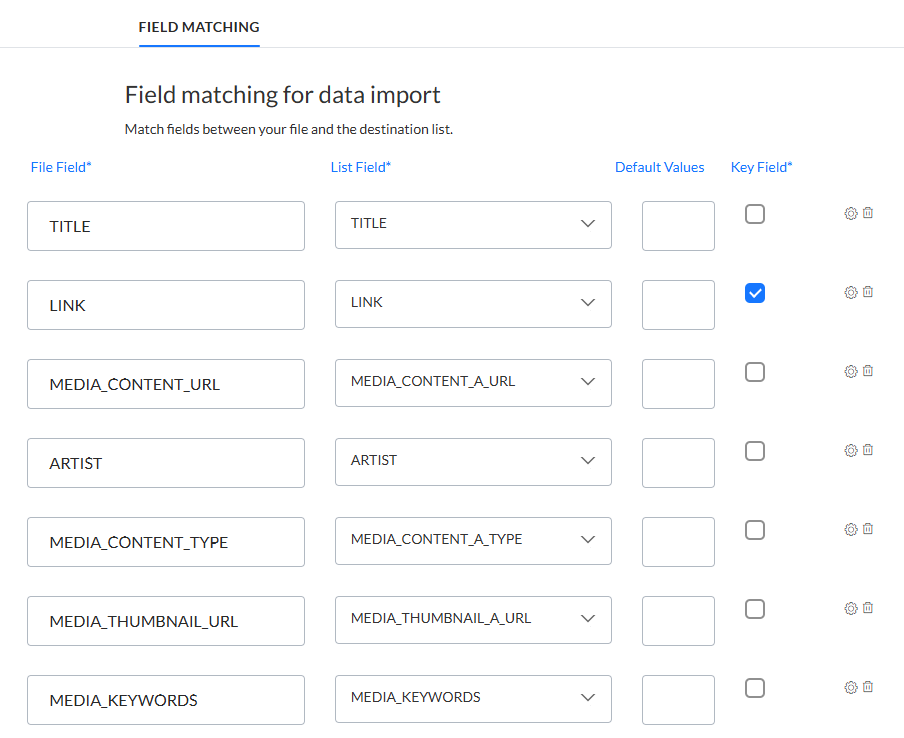
In diesem Beispiel können „media:content“ und alle seine Attribute abgeglichen werden, „media:category“ kann nicht für den Abgleich verwendet werden
<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<item>
...
<media:content url="http://www.foo.com/movie.mov" type="video/quicktime">
<media:category type="test">child 1</media:category>
</media:content>
...
</item>
</channel>
</rss>
Das Zahnrad-Symbol ermöglicht das Definieren zusätzlicher Optionen für die ausgewählte Feldzuordnung, wobei Daten in der Quelldatei durch Verwendung einer umgekehrten Recherche in einer Selligent-Liste umgewandelt werden. Diese umgekehrte Recherchefunktion kann für
- Felder verwendet werden, die mit Optionslisten verknüpft sind, wobei der Quellendateiwert durch den entsprechenden Code in der Selligent-Optionsliste ersetzt wird. Diese Funktion ist für Importe für jedweden Listentyp mit Ausnahme von Optionslisten verfügbar. Ersetzen Sie zum Beispiel den Wert „Männlich“ für das Geschlecht in der Quelldatei durch Code „100“ beim Importieren von Datensätzen, und ersetzen Sie „Weiblich“ durch Code „101“.
- Felder in Zielgruppenlisten, Datenauswahllisten, benutzerdefinierten Ereignislisten, wenn Feldwerte durch den Primärschlüssel in der Rechercheliste ersetzt werden. Je nach Art der Selligent-Liste, für die der Import durchgeführt wird, sind verschiedene Recherchen verfügbar:
- In Optionsliste importieren: Es ist keine umgekehrte Recherche verfügbar.
- In Datenliste importieren, Zielgruppenliste un benutzerdefinierte Ereignisliste: Eine Recherche ist in Optionsliste, Zielgruppenliste und Datenauswahlliste verfügbar.
- In Datenauswahlliste importieren: Recherche von Optionslistenwerten ist verfügbar.
Hinweis: Wenn die Option „Vorhandene Datensätze löschen“ in den Importeigenschaften ausgewählt ist, ist es nicht möglich, eine umgekehrte Recherche durchzuführen. Es kann keine Transformation erfolgen.
Beispiel 1: Ersetzen von Dateiwerten durch Optionslistencode
Beim Importieren einer Datei mit Kontakten in eine Zielgruppenliste, für die das Feld „Gender“ mit einer Optionsliste verknüpft ist, ist es möglich, diesen importieren Geschlechtswert durch den entsprechenden Code zu ersetzen, der in der Selligent-Optionsliste gespeichert ist.
Wir verwenden die Zielgruppenliste „Parana Customers Import“, bei der das Feld „Gender“ mit der Optionsliste „Gender_OptionList“ verknüpft ist.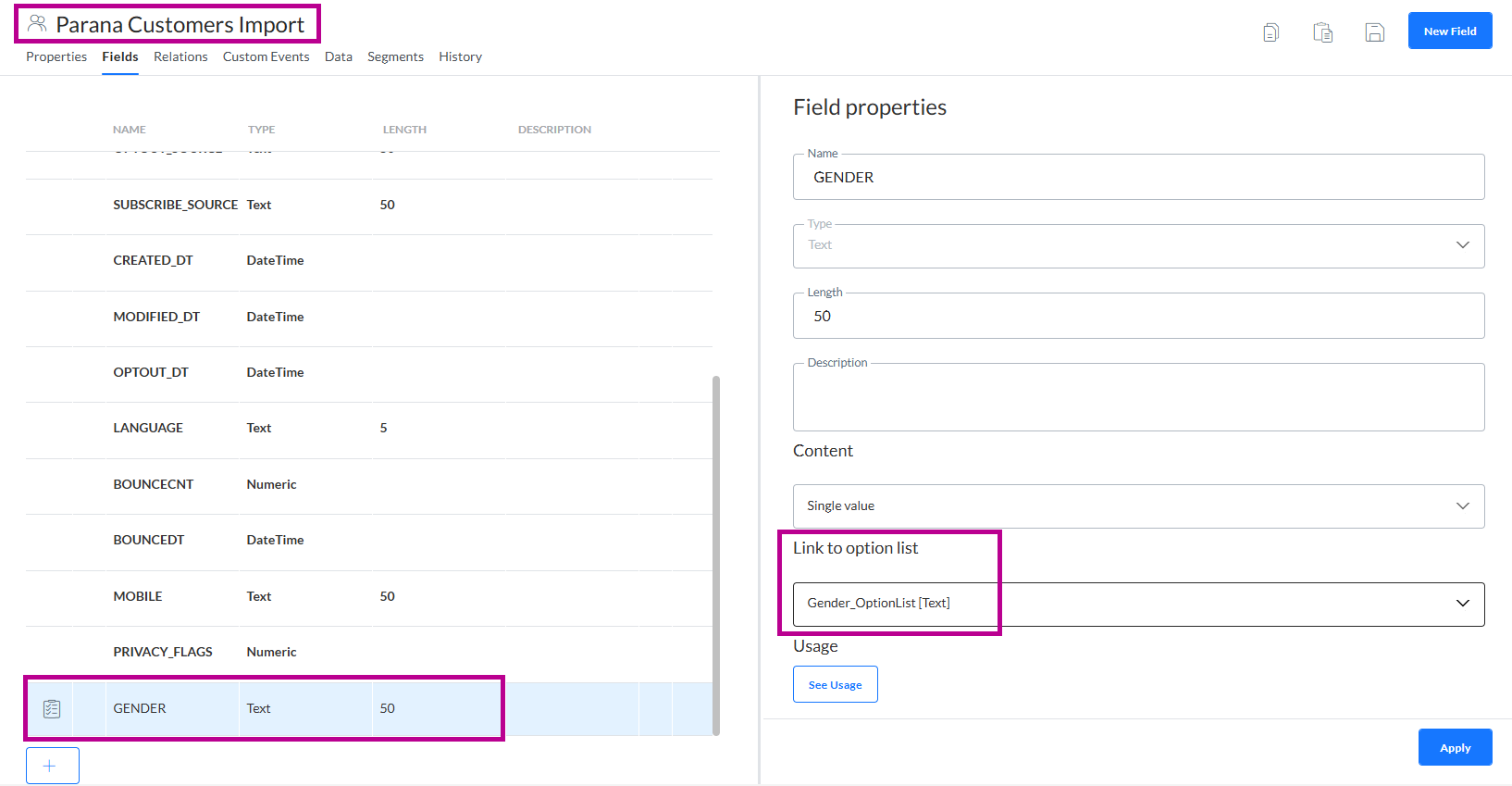
Die Optionsliste enthält die folgenden Daten: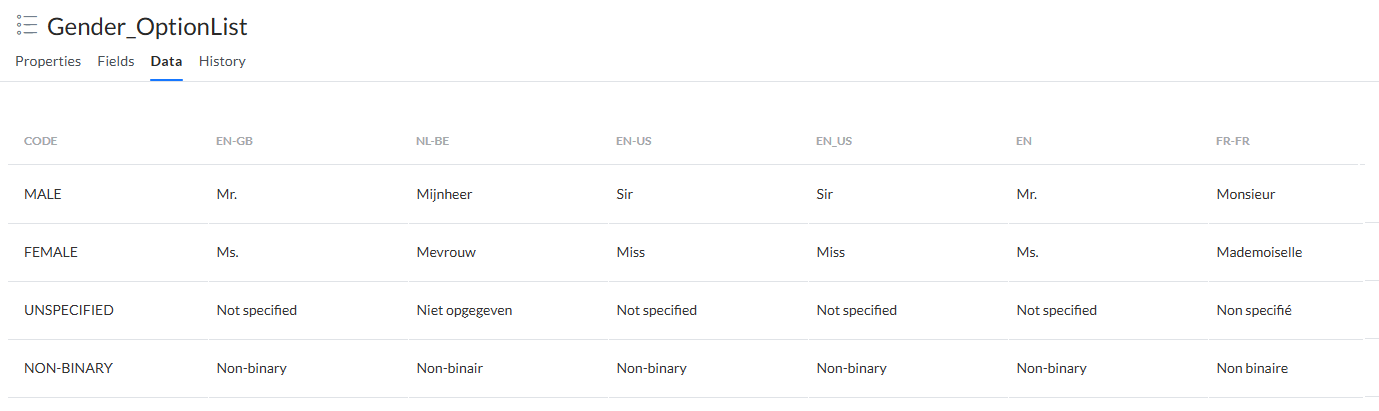
Um auf der Seite „Zuordnung“ eine Recherche in der Optionsliste durchzuführen und den Code abzurufen.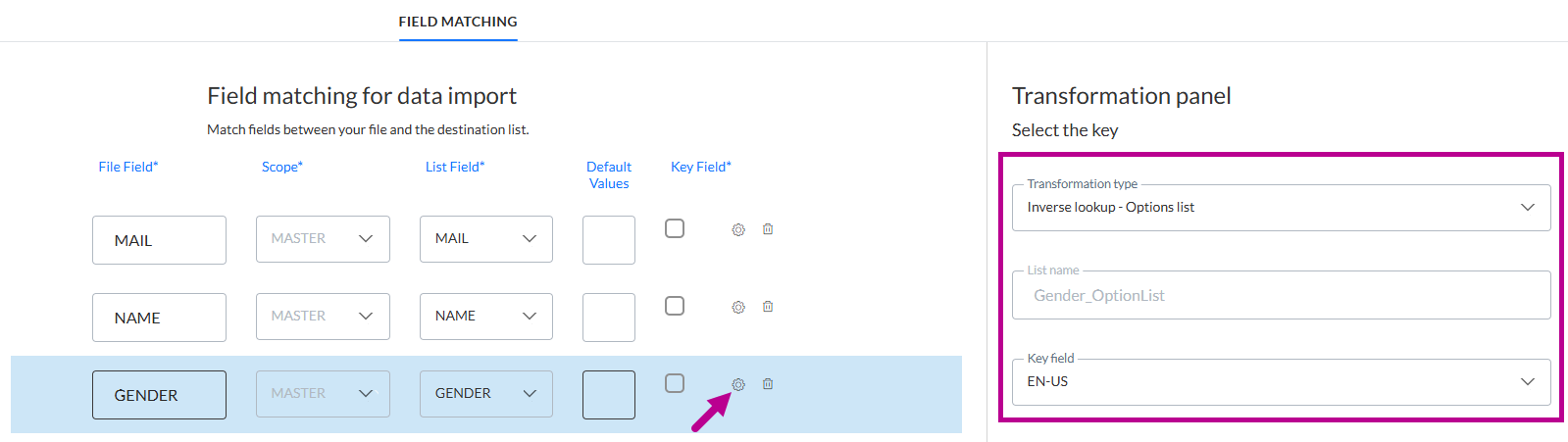 ,
,
Klicken Sie auf das Zahnrad-Symbol für die Zuordnung des Felds „Gender“ und wählen Sie „Umgekehrte Recherche – Optionsliste“ aus. Die Selligent-Optionsliste wird automatisch ausgefüllt. Dies ist möglich, weil das Feld „Gender“ in der Selligent-Zielgruppenliste mit der Optionsliste „Gender_OptionList“ verknüpft ist. Zuletzt wählen Sie eine Sprache aus dem Dropdown-Feld aus, um sicherzustellen, dass der Abgleich auf der richtigen Sprache basiert.
Hinweis: Dies impliziert, dass die Informationen in der Quelldatei immer in 1 Sprache verfügbar sind.
Als Folge wird eine Recherche in der Selligent-Optionsliste durchgeführt, um den Wert im Dateifeld mit einem Wert in der spezifischen Sprache in der Optionsliste abzugleichen und dann den entsprechenden Code statt dem ursprünglichen Wert zurückzugeben und zu speichern..
Beispiel 2: Ersetzen interner IDs durch primäre Selligent-Schlüssel.
Durchführen eines Imports in eine Datenliste und Ersetzen der externen Kennung K_USERID durch die in der Zielgruppenliste gespeicherte eindeutige Kennung „CONTACTPROFILE“. Dazu müssen wir eine umgekehrte Recherche in der Zielgruppenliste durchführen. Die Konfiguration ist wie folgt: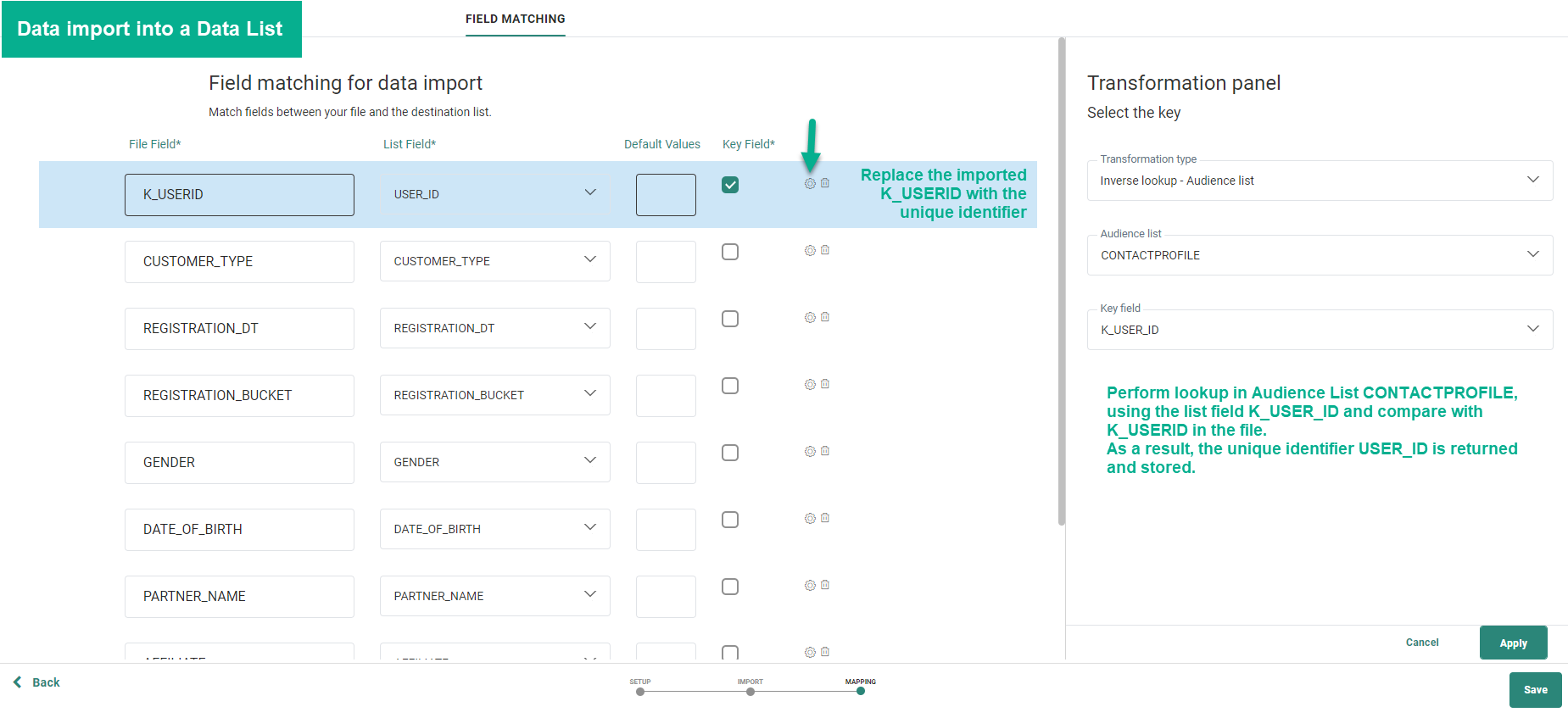
Basierend auf dem Abgleich zwischen dem Dateifeld K_USERID und dem Zielgruppenlistenfeld „K_USER_ID“ kann die eindeutige Kennung USER_ID abgerufen werden, um die externe ID zu ersetzen und sie zum Zeitpunkt des Imports in die Liste in der Datenliste zu speichern.
Fügen Sie so viele Felder wie nötig hinzu. Immer, wenn ein Abgleich definiert wird, wird automatisch eine neue Zeile zur Abgleichtabelle hinzugefügt.
Hinweis: Beim Durchführen einer umgekehrten Recherche in einer Datenauswahlliste, um die eingehenden Dateidaten in einen SCM-Wert zu transformieren, ist es möglich, das Dateifeld als optional für die Validierung einzustellen. Wenn diese Option eingestellt ist, wird, auch wenn kein Recherchewert für den Feldwert gefunden wird, der Datensatz trotzdem aktualisiert und nur die Aktualisierung des Felds wird übersprungen. Wenn das Feld als obligatorisch eingestellt ist und kein Recherchewert gefunden wird, wird die Aktualisierung des gesamten Datensatzes übersprungen.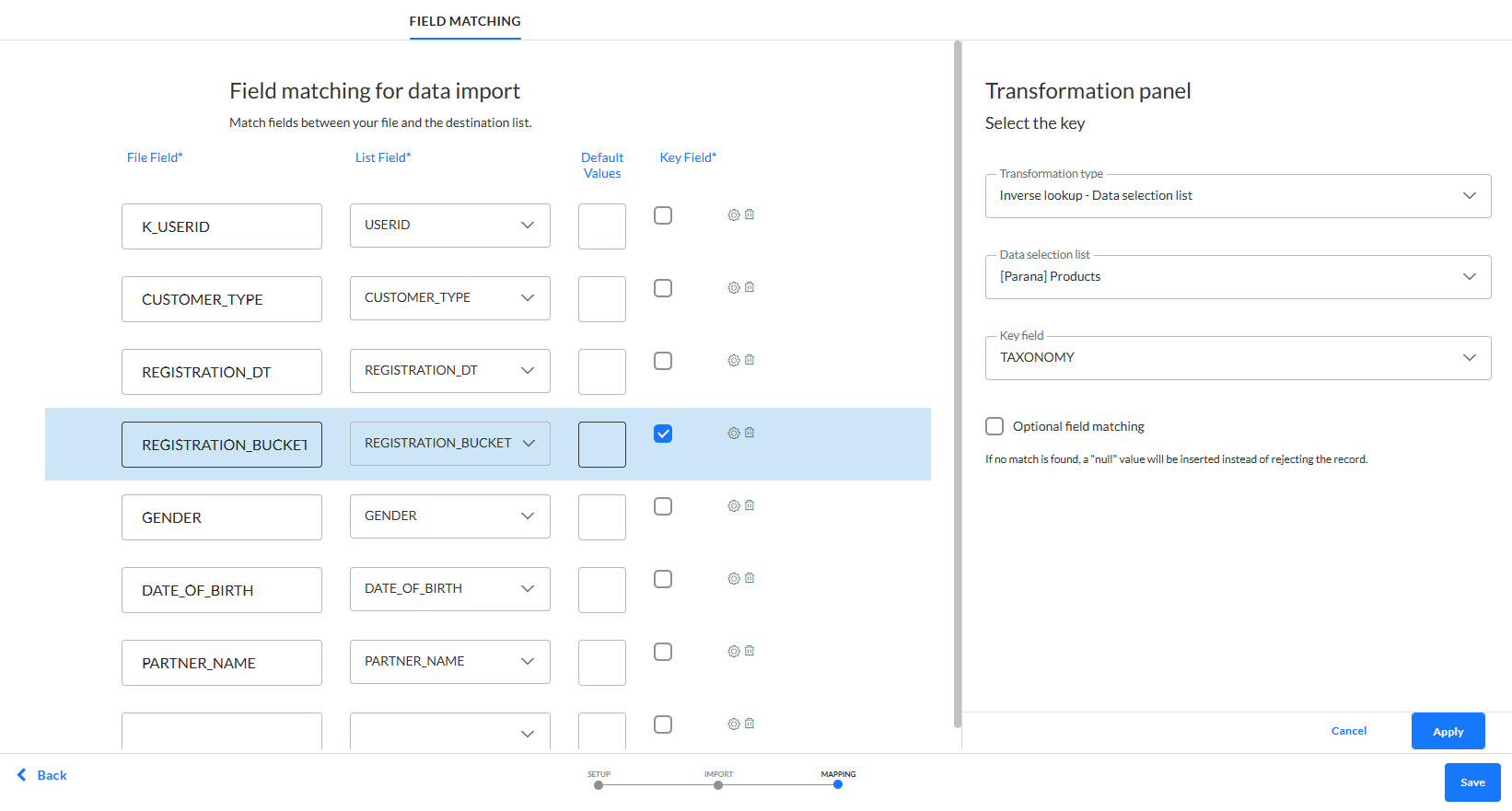
Klicken Sie, wenn Sie fertig sind, auf Speichern. Der Datenimport wird zum Start Seite hinzugefügt.
Verlauf
Sobald der Export konfiguriert ist, liefert eine Registerkarte „Verlauf“ Details zur Ausführung des Exports, der Dauer, dem Startdatum und Details, falls ein Fehler aufgetreten ist. Diese Information ist auf der Registerkarte „Ausführungsverlauf“ verfügbar.
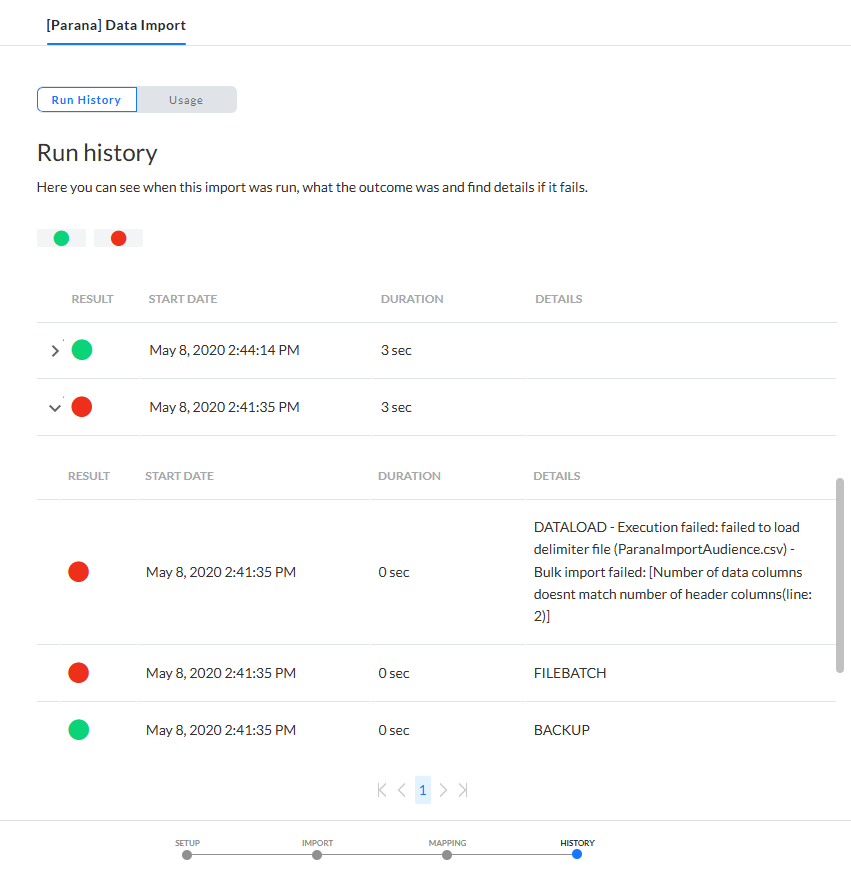
Die Registerkarte „Nutzung“ bietet Informationen dazu, wo der Datenimport verwendet wird.
